09-python爬虫01¶
[toc]
jupyter环境安装¶
什么是Jupyter Notebook¶
简介¶
Jupyter Notebook是基于网页的用于交互计算的应用程序。其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。——Jupyter Notebook官方介绍
简而言之,Jupyter Notebook是以网页的形式打开,可以在网页页面中**直接**编写代码和运行代码,代码的运行结果也会直接在代码块下显示。如在编程过程中需要编写说明文档,可在同一个页面中直接编写,便于作及时的说明和解释。
组成部分¶
① 网页应用
网页应用即基于网页形式的、结合了编写说明文档、数学公式、交互计算和其他富媒体形式的工具。简言之,网页应用是可以实现各种功能的工具。
② 文档
即Jupyter Notebook中所有交互计算、编写说明文档、数学公式、图片以及其他富媒体形式的输入和输出,都是以文档的形式体现的。
主要特点¶
- 编程时具有**语法高亮**、缩进、tab补全的功能。
- 可直接通过浏览器运行代码,同时在代码块下方展示运行结果。
- 对代码编写说明文档或语句时,支持Markdown语法。
安装 Jupyter Notebook¶
安装程序¶
① 安装前提
安装Jupyter Notebook的前提是需要安装了Python(3.3版本及以上,或2.7版本)。
② 使用Anaconda安装
如果你是小白,那么建议你通过安装Anaconda来解决Jupyter Notebook的安装问题,因为Anaconda已经自动为你安装了Jupter Notebook及其他工具,还有python中超过180个科学包及其依赖项。
你可以通过进入Anaconda的官方下载页面自行选择下载;如果你对阅读**英文文档**感到头痛,或者对**安装步骤**一无所知,甚至也想快速了解一下**什么是Anaconda**,那么可以前往我的另一篇文章Anaconda介绍、安装及使用教程。你想要的,都在里面!
常规来说,安装了Anaconda发行版时已经自动为你安装了Jupyter Notebook的,但如果没有自动安装,那么就在终端(Linux或macOS的“终端”,Windows的“Anaconda Prompt”,以下均简称“终端”)中输入以下命令安装:
conda install jupyter notebook
③ 使用pip命令安装
如果你是有经验的Python玩家,想要尝试用pip命令来安装Jupyter Notebook,那么请看以下步骤吧!接下来的命令都输入在终端当中的噢!
-
把pip升级到最新版本
-
Python 3.x
pip3 install --upgrade pip
- Python 2.x
pip install --upgrade pip
-
注意:老版本的pip在安装Jupyter Notebook过程中或面临依赖项无法同步安装的问题。因此**强烈建议**先把pip升级到最新版本。
-
安装Jupyter Notebook
- Python 3.x
pip3 install jupyter
- Python 2.x
pip install jupyter
运行 Jupyter Notebook¶
帮助命令¶
如果你有任何jupyter notebook命令的疑问,可以考虑查看官方帮助文档,命令如下:
jupyter notebook --help
或
jupyter notebook -h
启动程序¶
默认端口启动
在终端中输入以下命令:
jupyter notebook
执行命令之后,在终端中将会显示一系列notebook的服务器信息,同时浏览器将会自动启动Jupyter Notebook。
启动过程中终端显示内容如下:
$ jupyter notebook
[I 08:58:24.417 NotebookApp] Serving notebooks from local directory: /Users/catherine
[I 08:58:24.417 NotebookApp] 0 active kernels
[I 08:58:24.417 NotebookApp] The Jupyter Notebook is running at: http://localhost:8888/
[I 08:58:24.417 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
- 注意:之后在Jupyter Notebook的所有操作,都请保持终端**不要关闭**,因为一旦关闭终端,就会断开与本地服务器的链接,你将无法在Jupyter Notebook中进行其他操作啦。
浏览器地址栏中默认地将会显示:http://localhost:8888。其中,“localhost”指的是本机,“8888”则是端口号。
如果你**同时**启动了多个Jupyter Notebook,由于默认端口“8888”被占用,因此地址栏中的数字将从“8888”起,每多启动一个Jupyter Notebook数字就加1,如“8889”、“8890”……
② 指定端口启动
如果你想自定义端口号来启动Jupyter Notebook,可以在终端中输入以下命令:
jupyter notebook --port <port_number>
其中,“jupyter notebook --port 9999,即在端口号为“9999”的服务器启动Jupyter Notebook。
③ 启动服务器但不打开浏览器
如果你只是想启动Jupyter Notebook的服务器但不打算立刻进入到主页面,那么就无需立刻启动浏览器。在终端中输入:
jupyter notebook --no-browser
此时,将会在终端显示启动的服务器信息,并在服务器启动之后,显示出打开浏览器页面的链接。当你需要启动浏览器页面时,只需要复制链接,并粘贴在浏览器的地址栏中,轻按回车变转到了你的Jupyter Notebook页面。
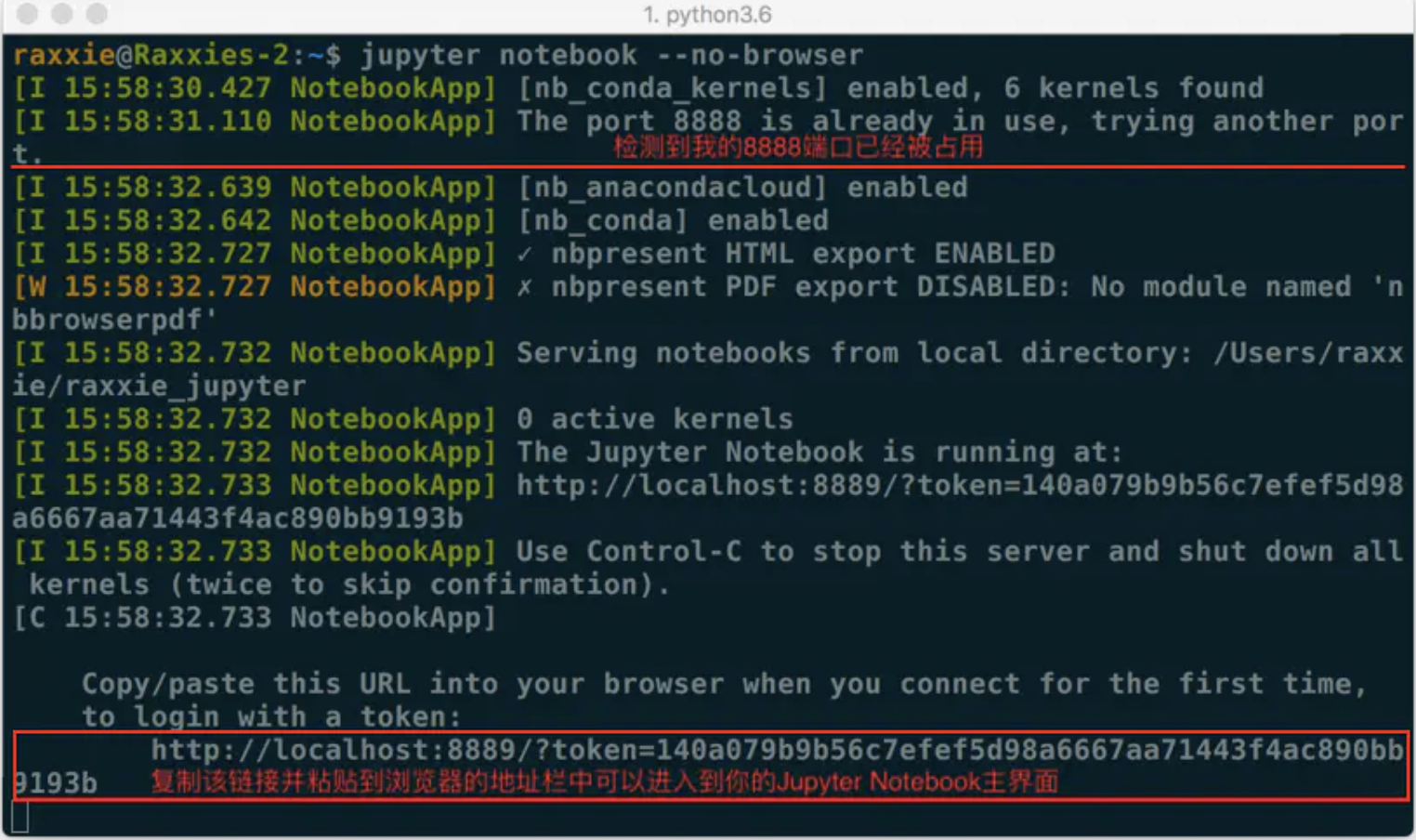
例图中由于在完成上面内容时我同时启动了多个Jupyter Notebook,因此显示我的“8888”端口号被占用,最终分配给我的是“8889”
使用快捷键¶
向上插入一个cell:a
向下插入一个cell:b
删除cell:x
将code切换成markdown:m
将markdown切换成code:y
运行cell:shift+enter
查看帮助文档:shift+tab
自动提示:tab
魔法指令¶
运行外部python源文件:%run xxx.py
计算statement的运行时间:%time statement
计算statement的平均运行时间:%timeit statement
测试多行代码的平均运行时间:
%%timeit
statement1
statement2
statement3
http和https协议¶
HTTP协议¶
1.官方概念:
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。(虽然童鞋们将这条概念都看烂了,但是也没办法,毕竟这就是HTTP的权威官方的概念解释,要想彻底理解,请客观目移下侧......)
2.白话概念:
HTTP协议就是服务器(Server)和客户端(Client)之间进行数据交互(相互传输数据)的一种形式。我们可以将Server和Client进行拟人化,那么该协议就是Server和Client这两兄弟间指定的一种交互沟通方式。大家都看过智取威虎山中杨子荣和土匪们之间说的黑话吧:
- 土匪:蘑菇,你哪路?什么价?(什么人?到哪里去?)
- 杨子荣:哈!想啥来啥,想吃奶来了妈妈,想娘家的人,孩子他舅舅来了。(找同行)
- 杨子荣:拜见三爷!
- 土匪:天王盖地虎!(你好大的胆!敢来气你的祖宗?)
- 杨子荣:宝塔镇河妖!(要是那样,叫我从山上摔死,掉河里淹死。)
- 土匪:野鸡闷头钻,哪能上天王山!(你不是正牌的。)
- 杨子荣:地上有的是米,喂呀,有根底!(老子是正牌的,老牌的。)
- 土匪:拜见过阿妈啦?(你从小拜谁为师?)
- 杨子荣:他房上没瓦,非否非,否非否!(不到正堂不能说。)
- 土匪:嘛哈嘛哈?(以前独干吗?)
- 杨子荣:正晌午说话,谁还没有家?(许大马棒山上。)
- 土匪:好叭哒!(内行,是把老手)
- 杨子荣:天下大耷拉!(不吹牛,闯过大队头。)
- 座山雕:脸红什么?
- 杨子荣:精神焕发!
- 座山雕:怎么又黄了?
- 杨子荣:防冷,涂的蜡!
- 座山雕:晒哒晒哒。(谁指点你来的?)
- 杨子荣:一座玲珑塔,面向青寨背靠沙!(是个道人。)
是不是看到这里,有得童鞋终于知道了传说中的‘天王盖地虎’是真正含义了吧。此黑话其实就是杨子荣和土匪之间进行交互沟通的方式(协议)。
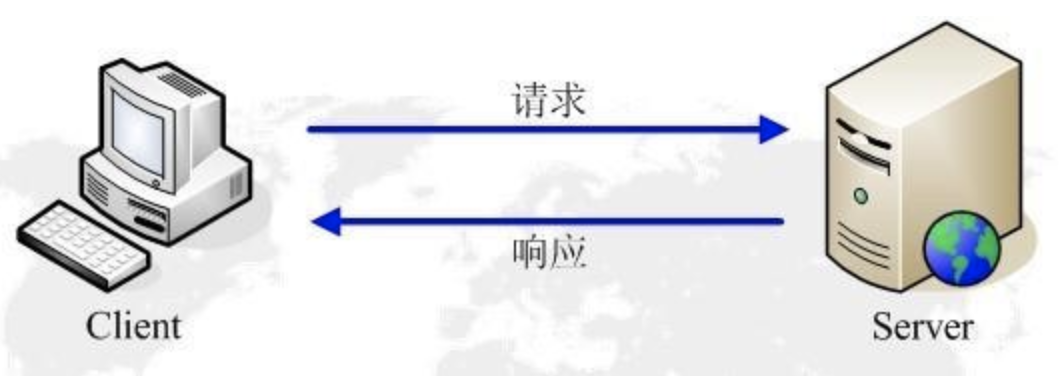
3.HTTP工作原理:
HTTP协议工作于客户端-服务端架构为上。浏览器作为HTTP客户端通过URL向HTTP服务端即WEB服务器发送所有请求。Web服务器根据接收到的请求后,向客户端发送响应信息。
4.HTTP四点注意事项:
- HTTP允许传输任意类型的数据对象。正在传输的类型由Content-Type加以标记。
- HTTP是无连接:无连接的含义是限制每次连接只处理一个请求。服务器处理完客户的请求,并收到客户的应答后,即断开连接。采用这种方式可以节省传输时间。
- HTTP是媒体独立的:这意味着,只要客户端和服务器知道如何处理的数据内容,任何类型的数据都可以通过HTTP发送。客户端以及服务器指定使用适合的MIME-type内容类型。
- HTTP是无状态:HTTP协议是无状态协议。无状态是指协议对于事务处理没有记忆能力。缺少状态意味着如果后续处理需要前面的信息,则它必须重传,这样可能导致每次连接传送的数据量增大。另一方面,在服务器不需要先前信息时它的应答就较快。
5.HTTP之URL:
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息
URL,全称是UniformResourceLocator, 中文叫统一资源定位符,是互联网上用来标识某一处资源的地址。以下面这个URL为例,介绍下普通URL的各部分组成:http://www.aspxfans.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name**从上面的URL可以看出,一个完整的URL包括以下几部分:
- 协议部分:该URL的协议部分为“http:”,这代表网页使用的是HTTP协议。在Internet中可以使用多种协议,如HTTP,FTP等等本例中使用的是HTTP协议。在"HTTP"后面的“//”为分隔符
- 域名部分:该URL的域名部分为“www.aspxfans.com”。一个URL中,也可以使用IP地址作为域名使用
- 端口部分:跟在域名后面的是端口,域名和端口之间使用“:”作为分隔符。端口不是一个URL必须的部分,如果省略端口部分,将采用默认端口
- 虚拟目录部分:从域名后的第一个“/”开始到最后一个“/”为止,是虚拟目录部分。虚拟目录也不是一个URL必须的部分。本例中的虚拟目录是“/news/”
- 文件名部分:从域名后的最后一个“/”开始到“?”为止,是文件名部分,如果没有“?”,则是从域名后的最后一个“/”开始到“#”为止,是文件部分,如果没有“?”和“#”,那么从域名后的最后一个“/”开始到结束,都是文件名部分。本例中的文件名是“index.asp”。文件名部分也不是一个URL必须的部分,如果省略该部分,则使用默认的文件名
- 锚部分:从“#”开始到最后,都是锚部分。本例中的锚部分是“name”。锚部分也不是一个URL必须的部分
- 参数部分:从“?”开始到“#”为止之间的部分为参数部分,又称搜索部分、查询部分。本例中的参数部分为“boardID=5&ID=24618&page=1”。参数可以允许有多个参数,参数与参数之间用“&”作为分隔符。
6.HTTP之Request:
客户端发送一个HTTP请求到服务器的请求消息包括以下组成部分:
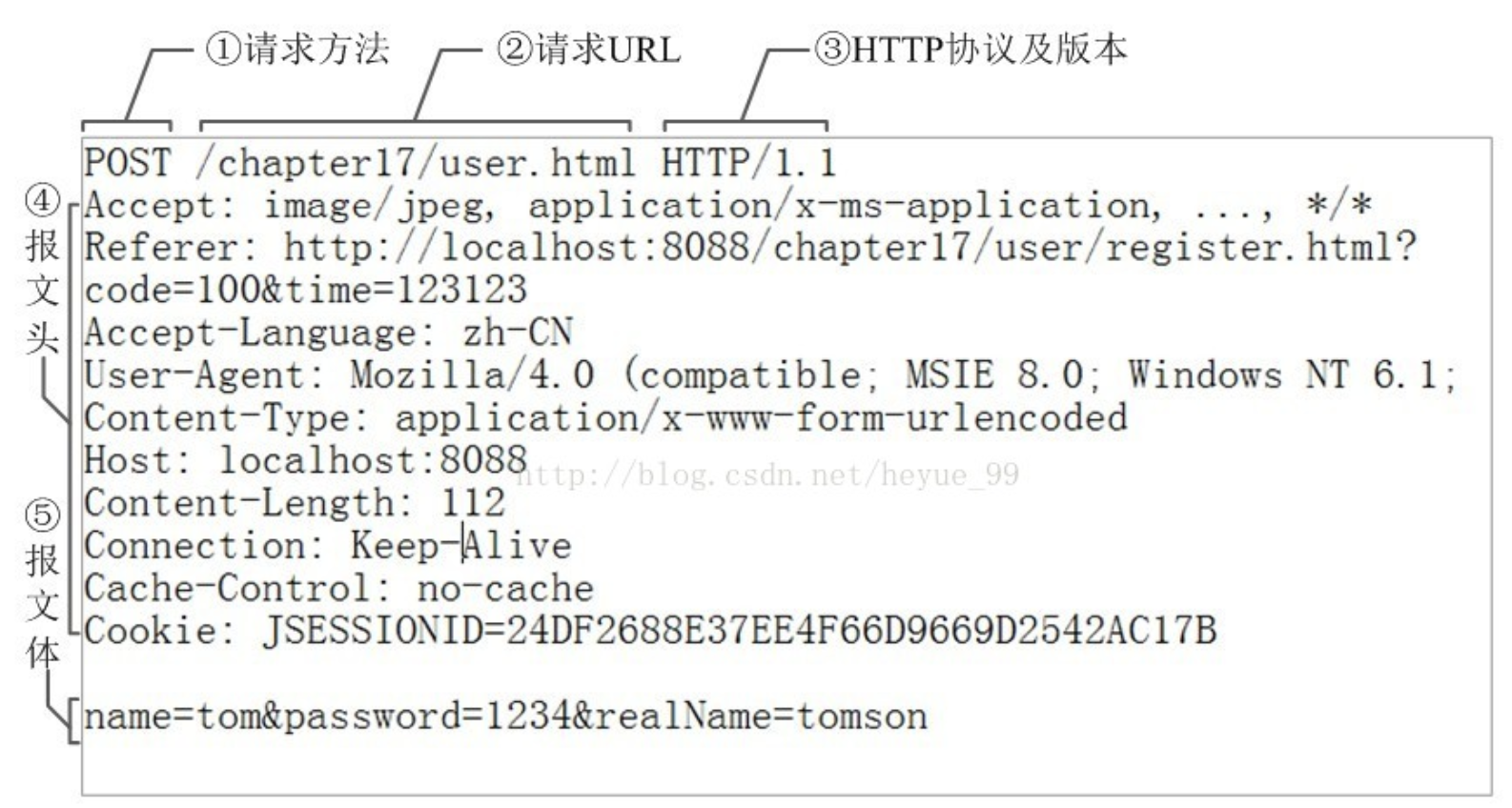
报文头:常被叫做请求头,请求头中存储的是该请求的一些主要说明(自我介绍)。服务器据此获取客户端的信息。
常见的请求头:
accept:浏览器通过这个头告诉服务器,它所支持的数据类型
Accept-Charset: 浏览器通过这个头告诉服务器,它支持哪种字符集 Accept-Encoding:浏览器通过这个头告诉服务器,支持的压缩格式 Accept-Language:浏览器通过这个头告诉服务器,它的语言环境 Host:浏览器通过这个头告诉服务器,想访问哪台主机 If-Modified-Since: 浏览器通过这个头告诉服务器,缓存数据的时间 Referer:浏览器通过这个头告诉服务器,客户机是哪个页面来的 防盗链 Connection:浏览器通过这个头告诉服务器,请求完后是断开链接还是何持链接 X-Requested-With: XMLHttpRequest 代表通过ajax方式进行访问
*User-Agent:请求载体的身份标识 *
报文体:常被叫做请求体,请求体中存储的是将要传输/发送给服务器的数据信息。
7.HTTP之Response:
服务器回传*一个HTTP响应到客户端的响应消息包括以下组成部分:*

状态码:以“清晰明确”的语言告诉客户端本次请求的处理结果。
HTTP的响应状态码由5段组成:
-
-
-
- 1xx 消息,一般是告诉客户端,请求已经收到了,正在处理,别急...
-
- 2xx 处理成功,一般表示:请求收悉、我明白你要的、请求已受理、已经处理完成等信息.
- 3xx 重定向到其它地方。它让客户端再发起一个请求以完成整个处理。
- 4xx 处理发生错误,责任在客户端,如客户端的请求一个不存在的资源,客户端未被授权,禁止访问等。
- 5xx 处理发生错误,责任在服务端,如服务端抛出异常,路由出错,HTTP版本不支持等。
-
相应头:响应的详情展示
常见的相应头信息:
Location: 服务器通过这个头,来告诉浏览器跳到哪里 Server:服务器通过这个头,告诉浏览器服务器的型号 Content-Encoding:服务器通过这个头,告诉浏览器,数据的压缩格式 Content-Length: 服务器通过这个头,告诉浏览器回送数据的长度 Content-Language: 服务器通过这个头,告诉浏览器语言环境 Content-Type:服务器通过这个头,告诉浏览器回送数据的类型 Refresh:服务器通过这个头,告诉浏览器定时刷新 Content-Disposition: 服务器通过这个头,告诉浏览器以下载方式打数据 Transfer-Encoding:服务器通过这个头,告诉浏览器数据是以分块方式回送的 Expires: -1 控制浏览器不要缓存 Cache-Control: no-cache Pragma: no-cache
相应体:根据客户端指定的请求信息,发送给客户端的指定数据
HTTPS协议¶
1.官方概念:
HTTPS (Secure Hypertext Transfer Protocol)安全超文本传输协议,HTTPS是在HTTP上建立SSL加密层,并对传输数据进行加密,是HTTP协议的安全版。
2.白话概念:
加密安全版的HTTP协议。
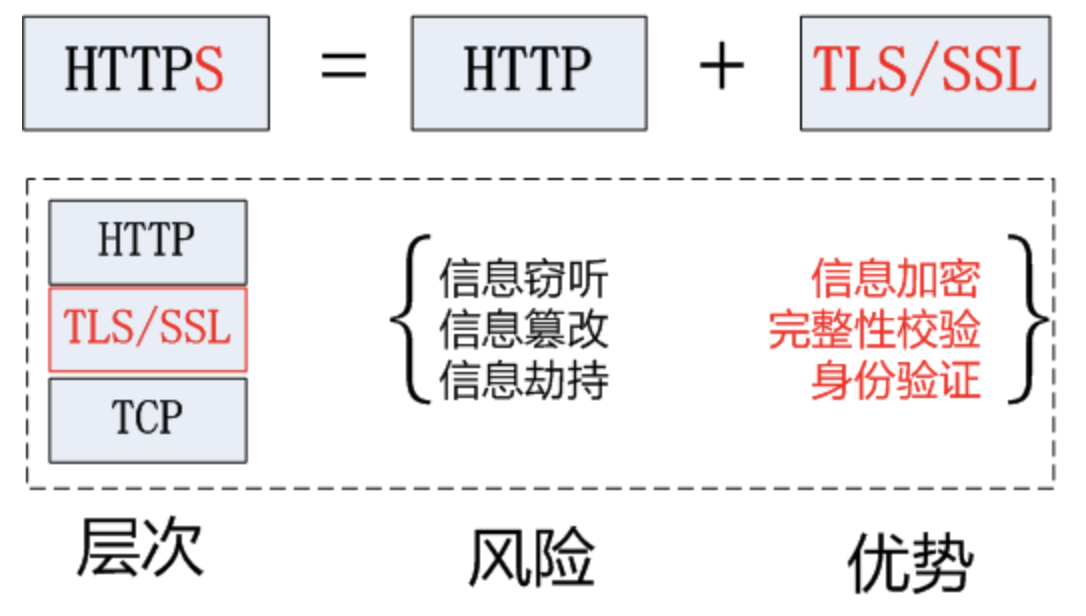
3.HTTPS采用的加密技术
3.1 SSL加密技术
SSL采用的加密技术叫做“共享密钥加密”,也叫作“对称密钥加密”,这种加密方法是这样的,比如客户端向服务器发送一条信息,首先客户端会采用已知的算法对信息进行加密,比如MD5或者Base64加密,接收端对加密的信息进行解密的时候需要用到密钥,中间会传递密钥,(加密和解密的密钥是同一个),密钥在传输中间是被加密的。这种方式看起来安全,但是仍有潜在的危险,一旦被窃听,或者信息被挟持,就有可能破解密钥,而破解其中的信息。因此“共享密钥加密”这种方式存在安全隐患:
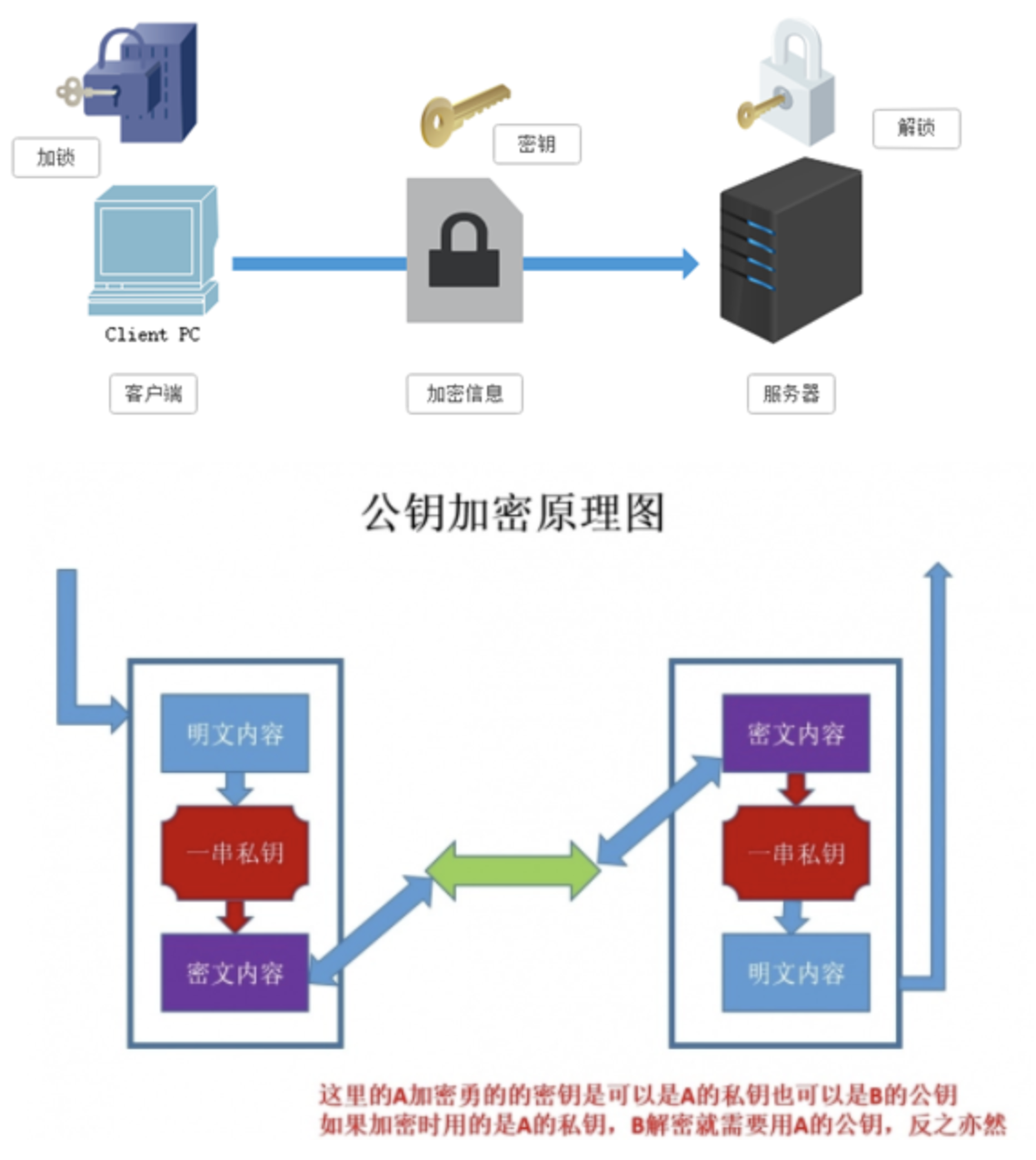
3.2 非对称秘钥加密技术
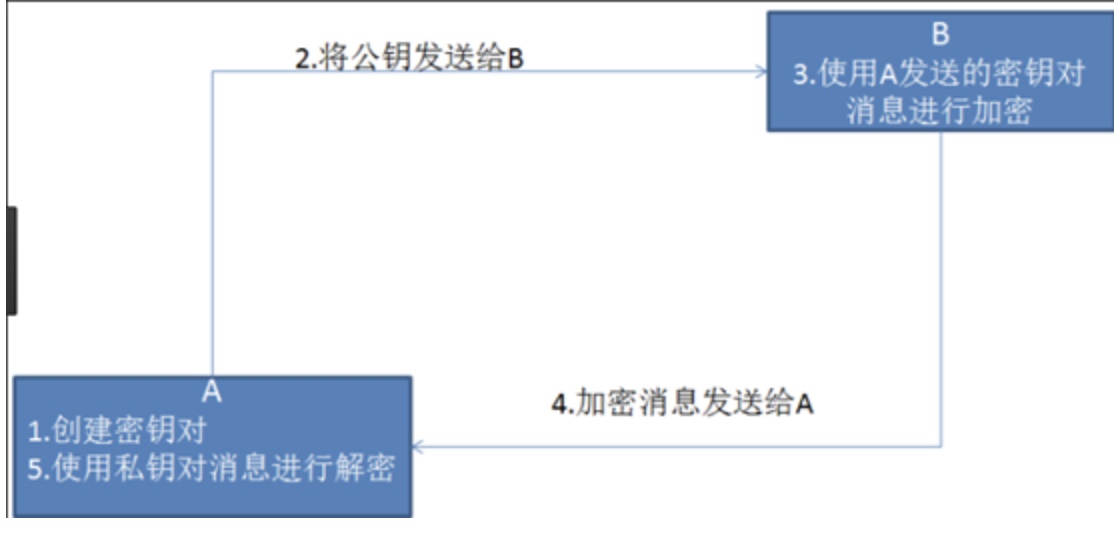
“非对称加密”使用的时候有两把锁,一把叫做“私有密钥”,一把是“公开密钥”,使用非对象加密的加密方式的时候,服务器首先告诉客户端按照自己给定的公开密钥进行加密处理,客户端按照公开密钥加密以后,服务器接受到信息再通过自己的私有密钥进行解密,这样做的好处就是解密的钥匙根本就不会进行传输,因此也就避免了被挟持的风险。就算公开密钥被窃听者拿到了,它也很难进行解密,因为解密过程是对离散对数求值,这可不是轻而易举就能做到的事。以下是非对称加密的原理图:
但是非对称秘钥加密技术也存在如下缺点:
第一个是:如何保证接收端向发送端发出公开秘钥的时候,发送端确保收到的是预先要发送的,而不会被挟持。只要是发送密钥,就有可能有被挟持的风险。
第二个是:非对称加密的方式效率比较低,它处理起来更为复杂,通信过程中使用就有一定的效率问题而影响通信速度
4.https的证书机制
在上面我们讲了非对称加密的缺点,其中第一个就是公钥很可能存在被挟持的情况,无法保证客户端收到的公开密钥就是服务器发行的公开密钥。此时就引出了公开密钥证书机制。数字证书认证机构是客户端与服务器都可信赖的第三方机构。证书的具体传播过程如下:
1:服务器的开发者携带公开密钥,向数字证书认证机构提出公开密钥的申请,数字证书认证机构在认清申请者的身份,审核通过以后,会对开发者申请的公开密钥做数字签名,然后分配这个已签名的公开密钥,并将密钥放在证书里面,绑定在一起
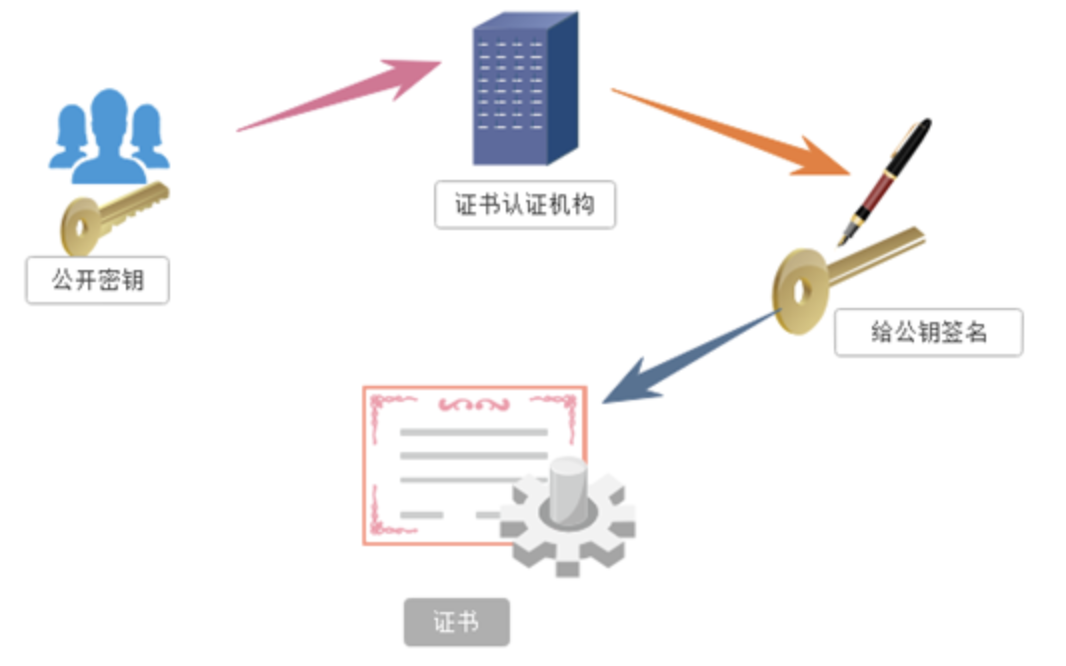
2:服务器将这份数字证书发送给客户端,因为客户端也认可证书机构,客户端可以通过数字证书中的数字签名来验证公钥的真伪,来确保服务器传过来的公开密钥是真实的。一般情况下,证书的数字签名是很难被伪造的,这取决于认证机构的公信力。一旦确认信息无误之后,客户端就会通过公钥对报文进行加密发送,服务器接收到以后用自己的私钥进行解密。
爬虫基础相关概念¶
爬虫介绍¶
引入
之前在授课过程中,好多同学都问过我这样的一个问题:为什么要学习爬虫,学习爬虫能够为我们以后的发展带来那些好处?其实学习爬虫的原因和为我们以后发展带来的好处都是显而易见的,无论是从实际的应用还是从就业上。
我们都知道,当前我们所处的时代是大数据的时代,在大数据时代,要进行数据分析,首先要有数据源,而学习爬虫,可以让我们获取更多的数据源,并且这些数据源可以按我们的目的进行采集。
优酷推出的火星情报局就是基于网络爬虫和数据分析制作完成的。其中每期的节目话题都是从相关热门的互动平台中进行相关数据的爬取,然后对爬取到的数据进行数据分析而得来的。另一方面,优酷根据用户实时观看视频时的前进,后退等行为数据,能够推测计算出观众的兴趣点和爱好点,这样有助于节目的剪辑和后期的节目方案的编写。
今日头条作为一个新闻推荐类的应用,其内部的新闻数据都是通过爬虫程序在各个新闻网站进行新闻数据的爬取,然后通过相应的处理和运算将用户感兴趣的新闻话题推送到用户的手机上。
从就业的角度来说,爬虫工程师目前来说属于紧缺人才,并且薪资待遇普遍较高所以,深层次地掌握这门技术,对于就业来说,是非常有利的。有些人学习爬虫可能为了就业或者跳槽。从这个角度来说,爬虫工程师是不错的选择之一。随着大数据时代的来临,爬虫技术的应用将越来越广泛,在未来会拥有更好的发展空间。
今日概要
- 爬虫简介
- 爬虫分类
- robots协议
- 反爬机制
- 反反爬机制
今日详情
什么是爬虫¶
爬虫就是通过编写程序模拟浏览器上网,然后让其去互联网上抓取数据的过程。
哪些语言可以实现爬虫¶
1.php:可以实现爬虫。php被号称是全世界最优美的语言(当然是其自己号称的,就是王婆卖瓜的意思),但是php在实现爬虫中支持多线程和多进程方面做的不好。
2.java:可以实现爬虫。java可以非常好的处理和实现爬虫,是唯一可以与python并驾齐驱且是python的头号劲敌。但是java实现爬虫代码较为臃肿,重构成本较大。
3.c、c++:可以实现爬虫。但是使用这种方式实现爬虫纯粹是是某些人(大佬们)能力的体现,却不是明智和合理的选择。
4.python:可以实现爬虫。python实现和处理爬虫语法简单,代码优美,支持的模块繁多,学习成本低,具有非常强大的框架(scrapy等)且一句难以言表的好!没有但是!
爬虫的分类¶
通用爬虫¶
通用爬虫是搜索引擎(Baidu、Google、Yahoo等)“抓取系统”的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。 简单来讲就是尽可能的;把互联网上的所有的网页下载下来,放到本地服务器里形成备分,在对这些网页做相关处理(提取关键字、去掉广告),最后提供一个用户检索接口。
- 搜索引擎如何抓取互联网上的网站数据?
- 门户网站主动向搜索引擎公司提供其网站的url
- 搜索引擎公司与DNS服务商合作,获取网站的url
- 门户网站主动挂靠在一些知名网站的友情链接中
聚焦爬虫¶
聚焦爬虫是根据指定的需求抓取网络上指定的数据。例如:获取豆瓣上电影的名称和影评,而不是获取整张页面中所有的数据值。
robots.txt协议¶
- 如果自己的门户网站中的指定页面中的数据不想让爬虫程序爬取到的话,那么则可以通过编写一个robots.txt的协议文件来约束爬虫程序的数据爬取。robots协议的编写格式可以观察淘宝网的robots(访问www.taobao.com/robots.txt即可)。但是需要注意的是,该协议只是相当于口头的协议,并没有使用相关技术进行强制管制,所以该协议是防君子不防小人。但是我们在学习爬虫阶段编写的爬虫程序可以先忽略robots协议。
反爬虫¶
- 门户网站通过相应的策略和技术手段,防止爬虫程序进行网站数据的爬取。
反反爬虫¶
- 爬虫程序通过相应的策略和技术手段,破解门户网站的反爬虫手段,从而爬取到相应的数据。
爬虫之requests模块01¶
简单概念¶
Requests 唯一的一个**非转基因**的 Python HTTP 库,人类可以安全享用。
警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症、冗余代码症、重新发明轮子症、啃文档症、抑郁、头疼、甚至死亡。
今日概要
- 基于requests的get请求
- 基于requests模块的post请求
- 基于requests模块ajax的get请求
- 基于requests模块ajax的post请求
- 综合项目练习:爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据
知识点回顾
-
常见的请求头
-
常见的相应头
-
https协议的加密方式
学习内容¶
- 什么是requests模块
- requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求。功能强大,用法简洁高效。在爬虫领域中占据着半壁江山的地位。
- 为什么要使用requests模块
- 因为在使用urllib模块的时候,会有诸多不便之处,总结如下:
- 手动处理url编码
- 手动处理post请求参数
- 处理cookie和代理操作繁琐
- ......
- 使用requests模块:
- 自动处理url编码
- 自动处理post请求参数
- 简化cookie和代理操作
- ......
- 如何使用requests模块
- 安装:
- pip install requests
- 使用流程
- 指定url
- 基于requests模块发起请求
- 获取响应对象中的数据值
- 持久化存储
- 通过5个基于requests模块的爬虫项目对该模块进行学习和巩固
- 基于requests模块的get请求
- 需求:爬取搜狗指定词条搜索后的页面数据
- 基于requests模块的post请求
- 需求:登录豆瓣电影,爬取登录成功后的页面数据
- 基于requests模块ajax的get请求
- 需求:爬取豆瓣电影分类排行榜 https://movie.douban.com/中的电影详情数据
- 基于requests模块ajax的post请求
- 需求:爬取肯德基餐厅查询http://www.kfc.com.cn/kfccda/index.aspx中指定地点的餐厅数据
- 综合练习
- 需求:爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据http://125.35.6.84:81/xk/
爬取搜狗¶
需求:爬取搜狗指定词条搜索后的页面数据
import requests
import os
#指定搜索关键字
word = input('enter a word you want to search:')
#自定义请求头信息
headers={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}
#指定url
url = 'https://www.sogou.com/web'
#封装get请求参数
prams = {
'query':word,
'ie':'utf-8'
}
#发起请求
response = requests.get(url=url,params=param)
#获取响应数据
page_text = response.text
with open('./sougou.html','w',encoding='utf-8') as fp:
fp.write(page_text)
请求载体身份标识的伪装:
- User-Agent:请求载体身份标识,通过浏览器发起的请求,请求载体为浏览器,则该请求的User-Agent为浏览器的身份标识,使用爬虫程序发起的请求,则该请求的载体为爬虫程序,则该请求的User-Agent为爬虫程序的身份标识。可以通过判断该值来获知该请求的载体究竟是基于哪款浏览器还是基于爬虫程序。
- 反爬机制:某些门户网站会对访问该网站的请求中的User-Agent进行捕获和判断,如果该请求的UA为爬虫程序,则拒绝向该请求提供数据。
- 反反爬策略:将爬虫程序的UA伪装成某一款浏览器的身份标识。
爬取豆瓣电影排行¶
需求:爬取豆瓣电影分类排行榜 https://movie.douban.com/中的电影详情数据
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import urllib.request
if __name__ == "__main__":
#指定ajax-get请求的url(通过抓包进行获取)
url = 'https://movie.douban.com/j/chart/top_list?'
#定制请求头信息,相关的头信息必须封装在字典结构中
headers = {
#定制请求头中的User-Agent参数,当然也可以定制请求头中其他的参数
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
}
#定制get请求携带的参数(从抓包工具中获取)
param = {
'type':'5',
'interval_id':'100:90',
'action':'',
'start':'0',
'limit':'20'
}
#发起get请求,获取响应对象
response = requests.get(url=url,headers=headers,params=param)
#获取响应内容:响应内容为json串
print(response.text)
爬取肯德基餐厅¶
需求:爬取肯德基餐厅查询http://www.kfc.com.cn/kfccda/index.aspx中指定地点的餐厅数据
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import urllib.request
if __name__ == "__main__":
#指定ajax-post请求的url(通过抓包进行获取)
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
#定制请求头信息,相关的头信息必须封装在字典结构中
headers = {
#定制请求头中的User-Agent参数,当然也可以定制请求头中其他的参数
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
}
#定制post请求携带的参数(从抓包工具中获取)
data = {
'cname':'',
'pid':'',
'keyword':'北京',
'pageIndex': '1',
'pageSize': '10'
}
#发起post请求,获取响应对象
response = requests.get(url=url,headers=headers,data=data)
#获取响应内容:响应内容为json串
print(response.text)
爬取国家药品监督管理总局¶
需求:爬取国家药品监督管理总局中基于中华人民共和国化妆品生产许可证相关数据
import requests
from fake_useragent import UserAgent
ua = UserAgent(use_cache_server=False,verify_ssl=False).random
headers = {
'User-Agent':ua
}
url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsList'
pageNum = 3
for page in range(3,5):
data = {
'on': 'true',
'page': str(page),
'pageSize': '15',
'productName':'',
'conditionType': '1',
'applyname':'',
'applysn':''
}
json_text = requests.post(url=url,data=data,headers=headers).json()
all_id_list = []
for dict in json_text['list']:
id = dict['ID']#用于二级页面数据获取
#下列详情信息可以在二级页面中获取
# name = dict['EPS_NAME']
# product = dict['PRODUCT_SN']
# man_name = dict['QF_MANAGER_NAME']
# d1 = dict['XC_DATE']
# d2 = dict['XK_DATE']
all_id_list.append(id)
#该url是一个ajax的post请求
post_url = 'http://125.35.6.84:81/xk/itownet/portalAction.do?method=getXkzsById'
for id in all_id_list:
post_data = {
'id':id
}
response = requests.post(url=post_url,data=post_data,headers=headers)
#该请求响应回来的数据有两个,一个是基于text,一个是基于json的,所以可以根据content-type,来获取指定的响应数据
if response.headers['Content-Type'] == 'application/json;charset=UTF-8':
#print(response.json())
#进行json解析
json_text = response.json()
print(json_text['businessPerson'])
爬取onlyoffice更新数据¶
#!/usr/bin/env python
#_*_coding:utf-8_*_
"""
json解析时报错
json.load(filename)
json.loads(string)
一个从文件加载,一个从内存加载
"""
# 导入requests模块
import requests
import json
# 定义User-Agent
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36'
}
data = {"username": "admin@qq.com", "password": "123456"}
header = {"Content-Type": "application/json"}
url = "http://172.28.8.238/api/2.0/authentication.json"
auth = requests.post(url=url,data=data)
auth_dict = auth.json()
new_header = {"Authorization": auth_dict["response"]["token"]}
params = {
'StartIndex': '0',
'Count': '200',
'__': '259130',
}
url='http://172.28.8.238/api/2.0/feed/filter.json'
respones = requests.get(url=url,params=params,headers=new_header)
respones.encoding = 'utf-8'
page_text = respones.json()
update_list = page_text["response"]["feeds"]
f = open('onlyoffice_update_list.csv','w',encoding='utf8')
for update_data in update_list:
update_date_list = update_data['feed']
update_date_list_dict = json.loads(update_date_list)
ModifiedDate = update_date_list_dict['ModifiedDate']
Name = update_date_list_dict['ExtraLocation']
Title = update_date_list_dict['Title']
ItemUrl = 'http://172.28.8.238/' + update_date_list_dict['ItemUrl']
f.write(str(ModifiedDate)+','+str(Name)+','+str(Title)+','+str(ItemUrl)+'\n')
f.close()
爬取onlyoffice表格目录列表¶
#!/usr/bin/env python
#_*_coding:utf-8_*_
# 导入requests模块
import requests
import json
import xml
from xml.etree import ElementTree
import xmltodict
session = requests.Session()
# 定义User-Agent
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36'
}
data = {"username": "admin@qq.com", "password": "123456"}
header = {"Content-Type": "application/json"}
url = "http://172.28.8.238/api/2.0/authentication.json"
auth = session.post(url=url,data=data)
auth_dict = auth.json()
new_header = {"Authorization": auth_dict["response"]["token"]}
params = {
"Content-Type": "text/xml",
}
"""
'parentId': '485',
'from': '0',
'count': '30',
'filter': '0',
'subjectGroup': 'false',
'subjectID':'',
'withSubfolders': 'false',
'searchInContent': 'false',
'search':'',
'_': '1637661623768',
"""
url='http://172.28.8.238/Products/Files/Services/WCFService/service.svc/folders?parentId=485&from=0&count=200&filter=0&subjectGroup=false&subjectID=&withSubfolders=false&searchInContent=false&search=&_=1637661623768'
respones = session.post(url=url,data=params,headers=new_header)
respones.encoding = 'utf-8'
print(respones.text)
# 此处代码是将xml格式的数据转换为json格式
xmlparse = xmltodict.parse(respones.text)
#jsonstr = json.dumps(xmlparse,indent=1)
onlyoffic_xlsx_list = json.dumps(xmlparse,ensure_ascii=False)
onlyoffic_xlsx_list_json = json.loads(onlyoffic_xlsx_list)
onlyoffic_xlsx_list_json_json = onlyoffic_xlsx_list_json["composite_data"]["entries"]["entry"]
#print(onlyoffic_xlsx_list_json["composite_data"]["entries"]["entry"])
for onlyoffic_xlsx in onlyoffic_xlsx_list_json_json:
modified_on = onlyoffic_xlsx["modified_on"]
modified_by = onlyoffic_xlsx["modified_by"]
title = onlyoffic_xlsx["title"]
folder_id = onlyoffic_xlsx["folder_id"]["#text"]
id = onlyoffic_xlsx["id"]["#text"]
print(modified_on,modified_by,title,folder_id,id)
爬取onlyoffice所有表格列表¶
#!/usr/bin/env python
#_*_coding:utf-8_*
# 导入requests模块
import requests
import json
import xml
from xml.etree import ElementTree
import xmltodict
session = requests.Session()
# 定义User-Agent
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36'
}
data = {"username": "admin@qq.com", "password": "123456"}
header = {"Content-Type": "application/json"}
url = "http://172.28.8.238/api/2.0/authentication.json"
auth = session.post(url=url,data=data)
auth_dict = auth.json()
new_header = {"Authorization": auth_dict["response"]["token"]}
params = {
"Content-Type": "text/xml",
}
url='http://172.28.8.238/Products/Files/Services/WCFService/service.svc/folders?parentId=485&from=0&count=300&filter=5&subjectGroup=false&subjectID=&withSubfolders=true&searchInContent=false&search=&_=1637721862246'
respones = session.post(url=url,data=params,headers=new_header)
respones.encoding = 'utf-8'
print(respones.text)
# 此处代码是将xml格式的数据转换为json格式
xmlparse = xmltodict.parse(respones.text)
#jsonstr = json.dumps(xmlparse,indent=1)
onlyoffic_xlsx_list = json.dumps(xmlparse,ensure_ascii=False)
onlyoffic_xlsx_list_json = json.loads(onlyoffic_xlsx_list)
onlyoffic_xlsx_list_json_json = onlyoffic_xlsx_list_json["composite_data"]["entries"]["entry"]
#print(onlyoffic_xlsx_list_json["composite_data"]["entries"]["entry"])
f = open('onlyoffice_xlsx_list.csv','w',encoding='utf8')
for onlyoffic_xlsx in onlyoffic_xlsx_list_json_json:
modified_on = onlyoffic_xlsx["modified_on"]
modified_by = onlyoffic_xlsx["modified_by"]
title = onlyoffic_xlsx["title"]
folder_id = onlyoffic_xlsx["folder_id"]["#text"]
id = onlyoffic_xlsx["id"]["#text"]
f.write(str(modified_on) + ',' + str(modified_by) + ',' + str(title) + ',' + str(folder_id) + ',' + str(id) + '\n')
print(modified_on,modified_by,title,folder_id,id)
f.close()
其他¶
- 爬取网络上的任意图片数据
- 爬取百度翻译的翻译结果数据值
- 爬取百度贴吧指定页码下的数据值
爬虫之requests模块02¶
数据爬取的流程¶
- 指定url
- 基于requests模块发起请求
- 获取响应对象中的数据
- 进行持久化存储
其实,在上述流程中还需要较为重要的一步,就是在持久化存储之前需要进行指定数据解析。因为大多数情况下的需求,我们都会指定去使用聚焦爬虫,也就是爬取页面中指定部分的数据值,而不是整个页面的数据。因此,本次课程中会给大家详细介绍讲解三种聚焦爬虫中的数据解析方式。至此,我们的数据爬取的流程可以修改为:
- 指定url
- 基于requests模块发起请求
- 获取响应中的数据
- 数据解析
- 进行持久化存储
今日概要
- 正则解析
- xpath解析
- bs4解析
知识点回顾
- requests模块的使用流程
- requests模块请求方法参数的作用
- 抓包工具抓取ajax的数据包
正则解析爬取¶
正则表达式详解¶
常用正则表达式回顾:
单字符:
. : 除换行以外所有字符
[] :[aoe] [a-w] 匹配集合中任意一个字符
\d :数字 [0-9]
\D : 非数字
\w :数字、字母、下划线、中文
\W : 非\w
\s :所有的空白字符包,括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。
\S : 非空白
数量修饰:
* : 任意多次 >=0
+ : 至少1次 >=1
? : 可有可无 0次或者1次
{m} :固定m次 hello{3,}
{m,} :至少m次
{m,n} :m-n次
边界:
$ : 以某某结尾
^ : 以某某开头
分组:
(ab)
贪婪模式: .*
非贪婪(惰性)模式: .*?
re.I : 忽略大小写
re.M :多行匹配
re.S :单行匹配
re.sub(正则表达式, 替换内容, 字符串)
简单练习(正则)¶
import re
#提取出python
key="javapythonc++php"
re.findall('python',key)[0]
#####################################################################
#提取出hello world
key="<html><h1>hello world<h1></html>"
re.findall('<h1>(.*)<h1>',key)[0]
#####################################################################
#提取170
string = '我喜欢身高为170的女孩'
re.findall('\d+',string)
#####################################################################
#提取出http://和https://
key='http://www.baidu.com and https://boob.com'
re.findall('https?://',key)
#####################################################################
#提取出hello
key='lalala<hTml>hello</HtMl>hahah' #输出<hTml>hello</HtMl>
re.findall('<[Hh][Tt][mM][lL]>(.*)</[Hh][Tt][mM][lL]>',key)
#####################################################################
#提取出hit.
key='bobo@hit.edu.com'#想要匹配到hit.
re.findall('h.*?\.',key)
#####################################################################
#匹配sas和saas
key='saas and sas and saaas'
re.findall('sa{1,2}s',key)
#####################################################################
#匹配出i开头的行
string = '''fall in love with you
i love you very much
i love she
i love her'''
re.findall('^.*',string,re.M)
#####################################################################
#匹配全部行
string1 = """<div>静夜思
窗前明月光
疑是地上霜
举头望明月
低头思故乡
</div>"""
re.findall('.*',string1,re.S)
爬取图片数据-urllib¶
#!/usr/bin/env python
#_*_coding:utf-8_*_
# 导入 requests urllib模块
import requests
import urllib
img_url = 'http://bpic.588ku.com/element_origin_min_pic/16/10/29/2ac8e99273bc079e40a8dc079ca11b1f.jpg'
# 可以直接对url发起请求并进行持久化存储
urllib.request.urlretrieve(img_url,'tupian2.jpg')
爬取图片数据-requests¶
#!/usr/bin/env python
#_*_coding:utf-8_*_
"""
如何爬取图片数据
- 方式1:基于requests
- 方式2:基于urllib
- urllib模块作用和requests模块一样,都是基于网络请求的模块
当requests问世后就迅速替代啦urllib模块
- 上述两种爬去图片的操作不同之处是什么?
- 使用urllib的方式爬取图片无法进行UA伪装,而requests的方式可以
"""
# 导入requests urllib模块
import requests
import urllib
# 定义User-Agent
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36'
}
img_url = 'http://bpic.588ku.com/element_origin_min_pic/16/10/29/2ac8e99273bc079e40a8dc079ca11b1f.jpg'
respones = requests.get(url=img_url,headers=headers)
# 返回的是二进制形式的响应数据
img_data = respones.content
with open('tupian.jpg','wb') as fp:
fp.write(img_data)
批量爬取图片¶
#!/usr/bin/env python
#_*_coding:utf-8_*_
"""
# 批量爬取网站中的图片
# www.521609.com
操作:需要将每一张图片的地址解析出来,然后对图片地址发送请求
1。捕获到当前首页的页面的源码数据
"""
# 批量爬取网站中的图片
# www.521609.com
# 导入requests re模块
import requests
import re
import os
import urllib
dirName = 'libs'
if not os.path.exists(dirName):
os.mkdir(dirName)
# 定义User-Agent
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.55 Safari/537.36'
}
# 1。捕获到当前首页的页面的源码数据
img_url='https://www.ivsky.com/tupian/dahai_v66784/'
page_text = requests.get(url=img_url,headers=headers).text
# 2.从当前获取的页面源码中解析出图片地址
#ex = '<li>.*?<img src="(.*?)" alt=.*?</li>'
ex = '<li>.*?<img src="(.*?)".*?</li>'
img_src_list = re.findall(ex,page_text,re.S)
for src in img_src_list:
src = 'https:'+src
imgPath = dirName+'/'+src.split('/')[-1]
urllib.request.urlretrieve(src,imgPath)
print(imgPath,'下载成功')