02-Shell编程实战¶
Shell变量¶
变量是任何一种编程语言都必不可少的组成部分,变量用来存放各种数据。脚本语言在定义变量时通常不需要指明类型,直接赋值就可以,Shell 变量也遵循这个规则。
在 Bash shell 中,每一个变量的值都是字符串,无论你给变量赋值时有没有使用引号,值都会以字符串的形式存储。
这意味着,Bash shell 在默认情况下不会区分变量类型,即使你将整数和小数赋值给变量,它们也会被视为字符串,这一点和大部分的编程语言不同。例如在C语言或者 C++ 中,变量分为整数、小数、字符串、布尔等多种类型。
当然,如果有必要,你也可以使用 Shell declare 关键字显式定义变量的类型,但在一般情况下没有这个需求,Shell 开发者在编写代码时自行注意值的类型即可。
定义变量
Shell 支持以下三种定义变量的方式:
variable=value
variable='value'
variable="value"
variable 是变量名,value 是赋给变量的值。如果 value 不包含任何空白符(例如空格、Tab 缩进等),那么可以不使用引号;如果 value 包含了空白符,那么就必须使用引号包围起来。使用单引号和使用双引号也是有区别的,稍后我们会详细说明。
注意,赋值号=的周围不能有空格,这可能和你熟悉的大部分编程语言都不一样。
Shell 变量的命名规范和大部分编程语言都一样:
- 变量名由数字、字母、下划线组成;
- 必须以字母或者下划线开头;
- 不能使用 Shell 里的关键字(通过 help 命令可以查看保留关键字)。
变量定义举例:
url=http://c.biancheng.net/shell/
echo $url
name='C语言中文网'
echo $name
author="严长生"
echo $author
使用变量
使用一个定义过的变量,只要在变量名前面加美元符号$即可,如:
author="严长生"
echo $author
echo ${author}
变量名外面的花括号{ }是可选的,加不加都行,加花括号是为了帮助解释器识别变量的边界,比如下面这种情况:
skill="Java"
echo "I am good at ${skill}Script"
如果不给 skill 变量加花括号,写成echo "I am good at $skillScript",解释器就会把 $skillScript 当成一个变量(其值为空),代码执行结果就不是我们期望的样子了。
推荐给所有变量加上花括号{ },这是个良好的编程习惯。
修改变量的值
已定义的变量,可以被重新赋值,如:
url="http://c.biancheng.net"
echo ${url}
url="http://c.biancheng.net/shell/"
echo ${url}
第二次对变量赋值时不能在变量名前加$,只有在使用变量时才能加$。
单引号和双引号的区别
前面我们还留下一个疑问,定义变量时,变量的值可以由单引号' '包围,也可以由双引号" "包围,它们到底有什么区别呢?不妨以下面的代码为例来说明:
#!/bin/bash
url="http://c.biancheng.net"
website1='C语言中文网:${url}'
website2="C语言中文网:${url}"
echo $website1
echo $website2
运行结果: C语言中文网:${url} C语言中文网:http://c.biancheng.net
以单引号' '包围变量的值时,单引号里面是什么就输出什么,即使内容中有变量和命令(命令需要反引起来)也会把它们原样输出。这种方式比较适合定义显示纯字符串的情况,即不希望解析变量、命令等的场景。
以双引号" "包围变量的值时,输出时会先解析里面的变量和命令,而不是把双引号中的变量名和命令原样输出。这种方式比较适合字符串中附带有变量和命令并且想将其解析后再输出的变量定义。
我的建议:如果变量的内容是数字,那么可以不加引号;如果真的需要原样输出就加单引号;其他没有特别要求的字符串等最好都加上双引号,定义变量时加双引号是最常见的使用场景。
将命令的结果赋值给变量
Shell 也支持将命令的执行结果赋值给变量,常见的有以下两种方式:
variable=`command`
variable=$(command)
第一种方式把命令用反引号(位于 Esc 键的下方)包围起来,反引号和单引号非常相似,容易产生混淆,所以不推荐使用这种方式;第二种方式把命令用$()包围起来,区分更加明显,所以推荐使用这种方式。
例如,我在 demo 目录中创建了一个名为 log.txt 的文本文件,用来记录我的日常工作。下面的代码中,使用 cat 命令将 log.txt 的内容读取出来,并赋值给一个变量,然后使用 echo 命令输出。
[mozhiyan@localhost ~]$ cd demo
[mozhiyan@localhost demo]$ log=$(cat log.txt)
[mozhiyan@localhost demo]$ echo $log
严长生正在编写Shell教程,教程地址:http://c.biancheng.net/shell/
[mozhiyan@localhost demo]$ log=`cat log.txt`
[mozhiyan@localhost demo]$ echo $log
严长生正在编写Shell教程,教程地址:http://c.biancheng.net/shell/
只读变量
使用 readonly 命令可以将变量定义为只读变量,只读变量的值不能被改变。
下面的例子尝试更改只读变量,结果报错:
#!/bin/bash
myUrl="http://c.biancheng.net/shell/"
readonly myUrl
myUrl="http://c.biancheng.net/shell/"
运行脚本,结果如下:
bash: myUrl: This variable is read only.
删除变量
使用 unset 命令可以删除变量。语法:
unset variable_name
变量被删除后不能再次使用;unset 命令不能删除只读变量。
举个例子:
#!/bin/sh
myUrl="http://c.biancheng.net/shell/"
unset myUrl
echo $myUrl
上面的脚本没有任何输出。
变量的作用域¶
Shell 变量的作用域(Scope),就是 Shell 变量的有效范围(可以使用的范围)。
在不同的作用域中,同名的变量不会相互干涉,就好像 A 班有个叫小明的同学,B 班也有个叫小明的同学,虽然他们都叫小明(对应于变量名),但是由于所在的班级(对应于作用域)不同,所以不会造成混乱。但是如果同一个班级中有两个叫小明的同学,就必须用类似于“大小明”、“小小明”这样的命名来区分他们。
Shell 变量的作用域可以分为三种:
- 有的变量只能在函数内部使用,这叫做局部变量(local variable);
- 有的变量可以在当前 Shell 进程中使用,这叫做全局变量(global variable);
- 而有的变量还可以在子进程中使用,这叫做环境变量(environment variable)。
Shell 局部变量
Shell 也支持自定义函数,但是 Shell 函数和 C++、Java、C# 等其他编程语言函数的一个不同点就是:在 Shell 函数中定义的变量默认也是全局变量,它和在函数外部定义变量拥有一样的效果。请看下面的代码:
#!/bin/bash
#定义函数
function func(){
a=99
}
#调用函数
func
#输出函数内部的变量
echo $a
输出结果:
输出结果: 99
a 是在函数内部定义的,但是在函数外部也可以得到它的值,证明它的作用域是全局的,而不是仅限于函数内部。
要想变量的作用域仅限于函数内部,可以在定义时加上local命令,此时该变量就成了局部变量。请看下面的代码:
#!/bin/bash
#定义函数
function func(){
local a=99
}
#调用函数
func
#输出函数内部的变量
echo $a
输出结果为空,表明变量 a 在函数外部无效,是一个局部变量。
Shell 变量的这个特性和 JavaScript 中的变量是类似的。在 JavaScript 函数内部定义的变量,默认也是全局变量,只有加上var关键字,它才会变成局部变量。
Shell 全局变量
所谓全局变量,就是指变量在当前的整个 Shell 进程中都有效。每个 Shell 进程都有自己的作用域,彼此之间互不影响。在 Shell 中定义的变量,默认就是全局变量。
想要实际演示全局变量在不同 Shell 进程中的互不相关性,可在图形界面下同时打开两个 Shell,或使用两个终端远程连接到服务器(SSH)。
首先打开一个 Shell 窗口,定义一个变量 a 并赋值为 99,然后打印,这时在同一个 Shell 窗口中是可正确打印变量 a 的值的。然后再打开一个新的 Shell 窗口,同样打印变量 a 的值,但结果却为空,如图 1 所示。
这说明全局变量 a 仅仅在定义它的第一个 Shell 进程中有效,对新的 Shell 进程没有影响。这很好理解,就像小王家和小徐家都有一部电视机(变量名相同),但是同一时刻小王家和小徐家的电视中播放的节目可以是不同的(变量值不同)。
需要强调的是,全局变量的作用范围是当前的 Shell 进程,而不是当前的 Shell 脚本文件,它们是不同的概念。打开一个 Shell 窗口就创建了一个 Shell 进程,打开多个 Shell 窗口就创建了多个 Shell 进程,每个 Shell 进程都是独立的,拥有不同的进程 ID。在一个 Shell 进程中可以使用 source 命令执行多个 Shell 脚本文件,此时全局变量在这些脚本文件中都有效。
例如,现在有两个 Shell 脚本文件,分别是 a.sh 和 b.sh。a.sh 的代码如下:
#!/bin/bashecho $ab=200
b.sh 的代码如下:
#!/bin/bashecho $b
打开一个 Shell 窗口,输入以下命令:
[c.biancheng.net]$ a=99
[c.biancheng.net]$ . ./a.sh
99
[c.biancheng.net]$ . ./b.sh
200
这三条命令都是在一个进程中执行的,从输出结果可以发现,在 Shell 窗口中以命令行的形式定义的变量 a,在 a.sh 中有效;在 a.sh 中定义的变量 b,在 b.sh 中也有效,变量 b 的作用范围已经超越了 a.sh。
Shell 环境变量
全局变量只在当前 Shell 进程中有效,对其它 Shell 进程和子进程都无效。如果使用export命令将全局变量导出,那么它就在所有的子进程中也有效了,这称为“环境变量”。
环境变量被创建时所处的 Shell 进程称为父进程,如果在父进程中再创建一个新的进程来执行 Shell 命令,那么这个新的进程被称作 Shell 子进程。当 Shell 子进程产生时,它会继承父进程的环境变量为自己所用,所以说环境变量可从父进程传给子进程。不难理解,环境变量还可以传递给孙进程。
注意,两个没有父子关系的 Shell 进程是不能传递环境变量的,并且环境变量只能向下传递而不能向上传递,即“传子不传父”。
创建 Shell 子进程最简单的方式是运行 bash 命令,如图 2 所示。
通过exit命令可以一层一层地退出 Shell。
下面演示一下环境变量的使用:
[c.biancheng.net]$ a=22 #定义一个全局变量
[c.biancheng.net]$ echo $a #在当前Shell中输出a,成功
22
[c.biancheng.net]$ bash #进入Shell子进程
[c.biancheng.net]$ echo $a #在子进程中输出a,失败
[c.biancheng.net]$ exit #退出Shell子进程,返回上一级Shell
exit
[c.biancheng.net]$ export a #将a导出为环境变量
[c.biancheng.net]$ bash #重新进入Shell子进程
[c.biancheng.net]$ echo $a #在子进程中再次输出a,成功
22
[c.biancheng.net]$ exit #退出Shell子进程
exit
[c.biancheng.net]$ exit #退出父进程,结束整个Shell会话
可以发现,默认情况下,a 在 Shell 子进程中是无效的;使用 export 将 a 导出为环境变量后,在子进程中就可以使用了。
export a这种形式是在定义变量 a 以后再将它导出为环境变量,如果想在定义的同时导出为环境变量,可以写作export a=22。
我们一直强调的是环境变量在 Shell 子进程中有效,并没有说它在所有的 Shell 进程中都有效;如果你通过终端创建了一个新的 Shell 窗口,那它就不是当前 Shell 的子进程,环境变量对这个新的 Shell 进程仍然是无效的。请看下图:
第一个窗口中的环境变量 a 在第二个窗口中就无效。
环境变量也是临时的
通过 export 导出的环境变量只对当前 Shell 进程以及所有的子进程有效,如果最顶层的父进程被关闭了,那么环境变量也就随之消失了,其它的进程也就无法使用了,所以说环境变量也是临时的。
有读者可能会问,如果我想让一个变量在所有 Shell 进程中都有效,不管它们之间是否存在父子关系,该怎么办呢?
只有将变量写入 Shell 配置文件中才能达到这个目的!Shell 进程每次启动时都会执行配置文件中的代码做一些初始化工作,如果将变量放在配置文件中,那么每次启动进程都会定义这个变量。
Shell命令替换¶
Shell 命令替换是指将命令的输出结果赋值给某个变量。比如,在某个目录中输入 ls 命令可查看当前目录中所有的文件,但如何将输出内容存入某个变量中呢?这就需要使用命令替换了,这也是 Shell 编程中使用非常频繁的功能。
Shell 中有两种方式可以完成命令替换,一种是反引号,一种是$(),使用方法如下:
variable=commands
variable=$(commands)
其中,variable 是变量名,commands 是要执行的命令。commands 可以只有一个命令,也可以有多个命令,多个命令之间以分号;分隔。
例如,date 命令用来获得当前的系统时间,使用命令替换可以将它的结果赋值给一个变量。
#!/bin/bash
begin_time=`date` #开始时间,使用``替换
sleep 20s #休眠20秒
finish_time=$(date) #结束时间,使用$()替换
echo "Begin time: $begin_time"
echo "Finish time: $finish_time"
运行脚本,20 秒后可以看到输出结果: Begin time: 2019年 04月 19日 星期五 09:59:58 CST Finish time: 2019年 04月 19日 星期五 10:00:18 CST
使用 data 命令的%s格式控制符可以得到当前的 UNIX 时间戳,这样就可以直接计算脚本的运行时间了。UNIX 时间戳是指从 1970 年 1 月 1 日 00:00:00 到目前为止的秒数,不了解的读者请猛击这里。
#!/bin/bash
begin_time=`date +%s` #开始时间,使用``替换
sleep 20s #休眠20秒
finish_time=$(date +%s) #结束时间,使用$()替换
run_time=$((finish_time - begin_time)) #时间差
echo "begin time: $begin_time"
echo "finish time: $finish_time"
echo "run time: ${run_time}s"
运行脚本,20 秒后可以看到输出结果: begin time: 1555639864 finish time: 1555639884 run time: 20s
第 6 行代码中的(( ))是 Shell 数学计算命令。和 C++、C#、Java 等编程语言不同,在 Shell 中进行数据计算不那么方便,必须使用专门的数学计算命令,(( ))就是其中之一。更多细节我们将会在《Shell数学计算》一节中详细讲解。
注意,如果被替换的命令的输出内容包括多行(也即有换行符),或者含有多个连续的空白符,那么在输出变量时应该将变量用双引号包围,否则系统会使用默认的空白符来填充,这会导致换行无效,以及连续的空白符被压缩成一个。请看下面的代码:
#!/bin/bash
LSL=`ls -l`
echo $LSL #不使用双引号包围
echo "--------------------------" #输出分隔符
echo "$LSL" #使用引号包围
运行结果:
total 8 drwxr-xr-x. 2 root root 21 7月 1 2016 abc -rw-rw-r--. 1 mozhiyan mozhiyan 147 10月 31 10:29 demo.sh -rw-rw-r--. 1 mozhiyan mozhiyan 35 10月 31 10:20 demo.sh~
--------------------------
total 8
drwxr-xr-x. 2 root root 21 7月 1 2016 abc
-rw-rw-r--. 1 mozhiyan mozhiyan 147 10月 31 10:29 demo.sh
-rw-rw-r--. 1 mozhiyan mozhiyan 35 10月 31 10:20 demo.sh~
所以,为了防止出现格式混乱的情况,我建议在输出变量时加上双引号。
再谈反引号和 $()
原则上讲,上面提到的两种变量替换的形式是等价的,可以随意使用;但是,反引号毕竟看起来像单引号,有时候会对查看代码造成困扰,而使用 $() 就相对清晰,能有效避免这种混乱。而且有些情况必须使用 ():() 支持嵌套,反引号不行。
下面的例子演示了使用计算 ls 命令列出的第一个文件的行数,这里使用了两层嵌套。
[c.biancheng.net]$ Fir_File_Lines=$(wc -l $(ls | sed -n '1p'))
[c.biancheng.net]$ echo "$Fir_File_Lines"
36 anaconda-ks.cfg
要注意的是,$() 仅在 Bash Shell 中有效,而反引号可在多种 Shell 中使用。所以这两种命令替换的方式各有特点,究竟选用哪种方式全看个人需求。
Shell位置参数¶
我们先来说一下 Shell 位置参数是怎么回事。
运行 Shell 脚本文件时我们可以给它传递一些参数,这些参数在脚本文件内部可以使用$n的形式来接收,例如,1 表示第一个参数,2 表示第二个参数,依次类推。
同样,在调用函数时也可以传递参数。Shell 函数参数的传递和其它编程语言不同,没有所谓的形参和实参,在定义函数时也不用指明参数的名字和数目。换句话说,定义 Shell 函数时不能带参数,但是在调用函数时却可以传递参数,这些传递进来的参数,在函数内部就也使用$n的形式接收,例如,1 表示第一个参数,2 表示第二个参数,依次类推。
这种通过$n的形式来接收的参数,在 Shell 中称为位置参数。
在讲解变量的命名时,我们提到:变量的名字必须以字母或者下划线开头,不能以数字开头;但是位置参数却偏偏是数字,这和变量的命名规则是相悖的,所以我们将它们视为“特殊变量”。
除了 n,Shell 中还有 #、、、@、?、$ 几个特殊参数,我们将在下节讲解。
1) 给脚本文件传递位置参数
请编写下面的代码,并命名为 test.sh:
#!/bin/bashecho "Language: $1"echo "URL: $2"
运行 test.sh,并附带参数:
[mozhiyan@localhost ~]$ cd demo
[mozhiyan@localhost demo]$ . ./test.sh Shell http://c.biancheng.net/shell/
Language: Shell
URL: http://c.biancheng.net/shell/
其中Shell是第一个位置参数,http://c.biancheng.net/shell/是第二个位置参数,两者之间以空格分隔。
2) 给函数传递位置参数
请编写下面的代码,并命名为 test.sh:
#!/bin/bash
#定义函数
function func(){
echo "Language: $1"
echo "URL: $2"
}
#调用函数
func C++ http://c.biancheng.net/cplus/
运行 test.sh:
[mozhiyan@localhost ~]$ cd demo
[mozhiyan@localhost demo]$ . ./test.sh
Language: C++
URL: http://c.biancheng.net/cplus/
关于函数定义和调用的具体语法请访问:Shell函数定义和调用、Shell函数参数
注意事项
如果参数个数太多,达到或者超过了 10 个,那么就得用${n}的形式来接收了,例如 {10}、{23}。{ }的作用是为了帮助解释器识别参数的边界,这跟使用变量时加{ }是一样的效果。
下节展望
在 Shell 中,传递位置参数时除了能单独取得某个具体的参数,还能取得所有参数的列表,以及参数的个数等信息,下节我们将会详细讲解。
Shell特殊变量¶
上节我们讲到了 n,它是特殊变量的一种,用来接收位置参数。本节我们继续讲解剩下的几个特殊变量,它们分别是:#、*、@、?、$。
| 变量 | 含义 |
|---|---|
| $0 | 当前脚本的文件名。 |
| $n(n≥1) | 传递给脚本或函数的参数。n 是一个数字,表示第几个参数。例如,第一个参数是 $1,第二个参数是 $2。 |
| $# | 传递给脚本或函数的参数个数。 |
| $* | 传递给脚本或函数的所有参数。 |
| $@ | 传递给脚本或函数的所有参数。当被双引号" "包含时,$@ 与 $* 稍有不同,我们将在《Shell *和@的区别》一节中详细讲解。 |
| $? | 上个命令的退出状态,或函数的返回值,我们将在《Shell $?》一节中详细讲解。 |
| $$ | 当前 Shell 进程 ID。对于 Shell 脚本,就是这些脚本所在的进程 ID。 |
下面我们通过两个例子来演示。
1) 给脚本文件传递参数
编写下面的代码,并保存为 test.sh:
#!/bin/bash
echo "Process ID: $$"
echo "File Name: $0"
echo "First Parameter : $1"
echo "Second Parameter : $2"
echo "All parameters 1: $@"
echo "All parameters 2: $*"
echo "Total: $#"
运行 test.sh,并附带参数:
[mozhiyan@localhost demo]$ . ./test.sh Shell Linux
Process ID: 5943
File Name: bash
First Parameter : Shell
Second Parameter : Linux
All parameters 1: Shell Linux
All parameters 2: Shell Linux
Total: 2
2) 给函数传递参数
编写下面的代码,并保存为 test.sh:
#!/bin/bash
#定义函数
function func(){
echo "Language: $1"
echo "URL: $2"
echo "First Parameter : $1"
echo "Second Parameter : $2"
echo "All parameters 1: $@"
echo "All parameters 2: $*"
echo "Total: $#"
}
#调用函数
func Java http://c.biancheng.net/java/
运行结果为:
Language: Java
URL: http://c.biancheng.net/java/
First Parameter : Java
Second Parameter : http://c.biancheng.net/java/
All parameters 1: Java http://c.biancheng.net/java/
All parameters 2: Java http://c.biancheng.net/java/
Total: 2
Shell特殊符号的区别¶
$* 和 $@ 都表示传递给函数或脚本的所有参数,我们已在《Shell特殊变量》一节中进行了演示,本节重点说一下它们之间的区别。
当 $* 和 $@ 不被双引号" "包围时,它们之间没有任何区别,都是将接收到的每个参数看做一份数据,彼此之间以空格来分隔。
但是当它们被双引号" "包含时,就会有区别了:
"$*"会将所有的参数从整体上看做一份数据,而不是把每个参数都看做一份数据。"$@"仍然将每个参数都看作一份数据,彼此之间是独立的。
比如传递了 5 个参数,那么对于"$*"来说,这 5 个参数会合并到一起形成一份数据,它们之间是无法分割的;而对于"$@"来说,这 5 个参数是相互独立的,它们是 5 份数据。
如果使用 echo 直接输出"$*"和"$@"做对比,是看不出区别的;但如果使用 for 循环来逐个输出数据,立即就能看出区别来。
编写下面的代码,并保存为 test.sh:
#!/bin/bashecho "print each param from \"\$*\""for var in "$*"do echo "$var"doneecho "print each param from \"\$@\""for var in "$@"do echo "$var"done
运行 test.sh,并附带参数:
[mozhiyan@localhost demo]$ . ./test.sh a b c d
print each param from "$*"
a b c d
print each param from "$@"
a
b
c
d
从运行结果可以发现,对于"$*",只循环了 1 次,因为它只有 1 分数据;对于"$@",循环了 5 次,因为它有 5 份数据。
shell返回值变量¶
$? 是一个特殊变量,用来获取上一个命令的退出状态,或者上一个函数的返回值。
所谓退出状态,就是上一个命令执行后的返回结果。退出状态是一个数字,一般情况下,大部分命令执行成功会返回 0,失败返回 1,这和C语言的 main() 函数是类似的。
不过,也有一些命令返回其他值,表示不同类型的错误。
1) $? 获取上一个命令的退出状态
编写下面的代码,并保存为 test.sh:
#!/bin/bash
if [ "$1" == 100 ]
then
exit 0 #参数正确,退出状态为0
else
exit 1 #参数错误,退出状态1
fi
exit表示退出当前 Shell 进程,我们必须在新进程中运行 test.sh,否则当前 Shell 会话(终端窗口)会被关闭,我们就无法取得它的退出状态了。
例如,运行 test.sh 时传递参数 100:
[mozhiyan@localhost ~]$ cd demo
[mozhiyan@localhost demo]$ bash ./test.sh 100 #作为一个新进程运行
[mozhiyan@localhost demo]$ echo $?
0
再如,运行 test.sh 时传递参数 89:
[mozhiyan@localhost demo]$ bash ./test.sh 89 #作为一个新进程运行
[mozhiyan@localhost demo]$ echo $?
1
2) $? 获取函数的返回值
编写下面的代码,并保存为 test.sh:
#!/bin/bash
#得到两个数相加的和
function add(){
return `expr $1 + $2`
}
add 23 50 #调用函数
echo $? #获取函数返回值
运行结果: 73
有 C++、C#、Java 等编程经验的读者请注意:严格来说,Shell 函数中的 return 关键字用来表示函数的退出状态,而不是函数的返回值;Shell 不像其它编程语言,没有专门处理返回值的关键字。
以上处理方案在其它编程语言中没有任何问题,但是在 Shell 中是非常错误的,Shell 函数的返回值和其它编程语言大有不同,我们将在《Shell函数返回值》中展开讨论。
Shell字符串详解¶
字符串(String)就是一系列字符的组合。字符串是 Shell 编程中最常用的数据类型之一(除了数字和字符串,也没有其他类型了)。
字符串可以由单引号' '包围,也可以由双引号" "包围,也可以不用引号。它们之间是有区别的,稍后我们会详解。
字符串举例:
str1=c.biancheng.net
str2="shell script"
str3='C语言中文网'
下面我们说一下三种形式的区别:
\1) 由单引号' '包围的字符串:
- 任何字符都会原样输出,在其中使用变量是无效的。
- 字符串中不能出现单引号,即使对单引号进行转义也不行。
\2) 由双引号" "包围的字符串:
- 如果其中包含了某个变量,那么该变量会被解析(得到该变量的值),而不是原样输出。
- 字符串中可以出现双引号,只要它被转义了就行。
\3) 不被引号包围的字符串
- 不被引号包围的字符串中出现变量时也会被解析,这一点和双引号
" "包围的字符串一样。 - 字符串中不能出现空格,否则空格后边的字符串会作为其他变量或者命令解析。
我们通过代码来演示一下三种形式的区别:
#!/bin/bash
n=74
str1=c.biancheng.net$n str2="shell \"script\" $n"
str3='C语言中文网 $n'
echo $str1
echo $str2
echo $str3
运行结果:
c.biancheng.net74 shell "script" 74 C语言中文网 $n
str1 中包含了$n,它被解析为变量 n 的引用。$n后边有空格,紧随空格的是 str2;Shell 将 str2 解释为一个新的变量名,而不是作为字符串 str1 的一部分。
str2 中包含了引号,但是被转义了(由反斜杠\开头的表示转义字符)。str2 中也包含了$n,它也被解析为变量 n 的引用。
str3 中也包含了$n,但是仅仅是作为普通字符,并没有解析为变量 n 的引用。
获取字符串长度
在 Shell 中获取字符串长度很简单,具体方法如下:
${#string_name}
string_name 表示字符串名字。
下面是具体的演示:
#!/bin/bash
str="http://c.biancheng.net/shell/"
echo ${#str}
运行结果: 29
Shell字符串拼接¶
在脚本语言中,字符串的拼接(也称字符串连接或者字符串合并)往往都非常简单,例如:
- 在 PHP 中,使用
.即可连接两个字符串; - 在 JavaScript 中,使用
+即可将两个字符串合并为一个。
然而,在 Shell 中你不需要使用任何运算符,将两个字符串并排放在一起就能实现拼接,非常简单粗暴。请看下面的例子:
#!/bin/bash
name="Shell"
url="http://c.biancheng.net/shell/"
str1=$name$url #中间不能有空格
str2="$name $url" #如果被双引号包围,那么中间可以有空格
str3=$name": "$url #中间可以出现别的字符串
str4="$name: $url" #这样写也可以
str5="${name}Script: ${url}index.html" #这个时候需要给变量名加上大括号
echo $str1
echo $str2
echo $str3
echo $str4
echo $str5
运行结果: Shellhttp://c.biancheng.net/shell/ Shell http://c.biancheng.net/shell/ Shell: http://c.biancheng.net/shell/ Shell: http://c.biancheng.net/shell/ ShellScript: http://c.biancheng.net/shell/index.html
对于第 7 行代码,$name 和 $url 之间之所以不能出现空格,是因为当字符串不被任何一种引号包围时,遇到空格就认为字符串结束了,空格后边的内容会作为其他变量或者命令解析,这一点在《Shell字符串》中已经提到。
对于第 10 行代码,加{ }是为了帮助解释器识别变量的边界,这一点在《Shell变量》中已经提到。
Shell 这种拼接字符串的方式和 Python 非常类似,Python 既支持用+拼接字符串,也支持将两个字符串放在一起,读者可以猛击《Python字符串》了解详情。
Shell字符串截取¶
hell 截取字符串通常有两种方式:从指定位置开始截取和从指定字符(子字符串)开始截取。
从指定位置开始截取
这种方式需要两个参数:除了指定起始位置,还需要截取长度,才能最终确定要截取的字符串。
既然需要指定起始位置,那么就涉及到计数方向的问题,到底是从字符串左边开始计数,还是从字符串右边开始计数。答案是 Shell 同时支持两种计数方式。
1) 从字符串左边开始计数
如果想从字符串的左边开始计数,那么截取字符串的具体格式如下:
${string: start :length}
其中,string 是要截取的字符串,start 是起始位置(从左边开始,从 0 开始计数),length 是要截取的长度(省略的话表示直到字符串的末尾)。
例如:
url="c.biancheng.net"echo ${url: 2: 9}
结果为biancheng。
再如:
url="c.biancheng.net"echo ${url: 2} #省略 length,截取到字符串末尾
结果为biancheng.net。
2) 从右边开始计数
如果想从字符串的右边开始计数,那么截取字符串的具体格式如下:
${string: 0-start :length}
同第 1) 种格式相比,第 2) 种格式仅仅多了0-,这是固定的写法,专门用来表示从字符串右边开始计数。
这里需要强调两点:
- 从左边开始计数时,起始数字是 0(这符合程序员思维);从右边开始计数时,起始数字是 1(这符合常人思维)。计数方向不同,起始数字也不同。
- 不管从哪边开始计数,截取方向都是从左到右。
例如:
url="c.biancheng.net"echo ${url: 0-13: 9}
结果为biancheng。从右边数,b是第 13 个字符。
再如:
url="c.biancheng.net"echo ${url: 0-13} #省略 length,直接截取到字符串末尾
结果为biancheng.net。
从指定字符(子字符串)开始截取
这种截取方式无法指定字符串长度,只能从指定字符(子字符串)截取到字符串末尾。Shell 可以截取指定字符(子字符串)右边的所有字符,也可以截取左边的所有字符。
1) 使用 # 号截取右边字符
使用#号可以截取指定字符(或者子字符串)右边的所有字符,具体格式如下:
${string#*chars}
其中,string 表示要截取的字符,chars 是指定的字符(或者子字符串),*是通配符的一种,表示任意长度的字符串。*chars连起来使用的意思是:忽略左边的所有字符,直到遇见 chars(chars 不会被截取)。
请看下面的例子:
url="http://c.biancheng.net/index.html"echo ${url#*:}
结果为//c.biancheng.net/index.html。
以下写法也可以得到同样的结果:
echo ${url#*p:}echo ${url#*ttp:}
如果不需要忽略 chars 左边的字符,那么也可以不写*,例如:
url="http://c.biancheng.net/index.html"echo ${url#http://}
结果为c.biancheng.net/index.html。
注意,以上写法遇到第一个匹配的字符(子字符串)就结束了。例如:
url="http://c.biancheng.net/index.html"echo ${url#*/}
结果为/c.biancheng.net/index.html。url 字符串中有三个/,输出结果表明,Shell 遇到第一个/就匹配结束了。
如果希望直到最后一个指定字符(子字符串)再匹配结束,那么可以使用##,具体格式为:
${string##*chars}
请看下面的例子:
#!/bin/bash
url="http://c.biancheng.net/index.html"
echo ${url#*/} #结果为 /c.biancheng.net/index.html
echo ${url##*/} #结果为 index.html
str="---aa+++aa@@@"
echo ${str#*aa} #结果为 +++aa@@@
echo ${str##*aa} #结果为 @@@
2) 使用 % 截取左边字符
使用%号可以截取指定字符(或者子字符串)左边的所有字符,具体格式如下:
${string%chars*}
请注意*的位置,因为要截取 chars 左边的字符,而忽略 chars 右边的字符,所以*应该位于 chars 的右侧。其他方面%和#的用法相同,这里不再赘述,仅举例说明:
#!/bin/bash
url="http://c.biancheng.net/index.html"
echo ${url%/*} #结果为 http://c.biancheng.net
echo ${url%%/*} #结果为 http:
str="---aa+++aa@@@"
echo ${str%aa*} #结果为 ---aa+++
echo ${str%%aa*} #结果为 ---
汇总
最后,我们对以上 8 种格式做一个汇总,请看下表:
| 格式 | 说明 |
|---|---|
| ${string: start :length} | 从 string 字符串的左边第 start 个字符开始,向右截取 length 个字符。 |
| ${string: start} | 从 string 字符串的左边第 start 个字符开始截取,直到最后。 |
| ${string: 0-start :length} | 从 string 字符串的右边第 start 个字符开始,向右截取 length 个字符。 |
| ${string: 0-start} | 从 string 字符串的右边第 start 个字符开始截取,直到最后。 |
| ${string#*chars} | 从 string 字符串第一次出现 *chars 的位置开始,截取 *chars 右边的所有字符。 |
| ${string##*chars} | 从 string 字符串最后一次出现 *chars 的位置开始,截取 *chars 右边的所有字符。 |
| ${string%*chars} | 从 string 字符串第一次出现 *chars 的位置开始,截取 *chars 左边的所有字符。 |
| ${string%%*chars} | 从 string 字符串最后一次出现 *chars 的位置开始,截取 *chars 左边的所有字符。 |
Shell数组入门¶
和其他编程语言一样,Shell 也支持数组。数组(Array)是若干数据的集合,其中的每一份数据都称为元素(Element)。
Shell 并且没有限制数组的大小,理论上可以存放无限量的数据。和 C++、Java、C# 等类似,Shell 数组元素的下标也是从 0 开始计数。
获取数组中的元素要使用下标[ ],下标可以是一个整数,也可以是一个结果为整数的表达式;当然,下标必须大于等于 0。
遗憾的是,常用的 Bash Shell 只支持一维数组,不支持多维数组。
Shell数组的定义¶
在 Shell 中,用括号( )来表示数组,数组元素之间用空格来分隔。由此,定义数组的一般形式为:
array_name=(ele1 ele2 ele3 ... elen)
注意,赋值号=两边不能有空格,必须紧挨着数组名和数组元素。
下面是一个定义数组的实例:
nums=(29 100 13 8 91 44)
Shell 是弱类型的,它并不要求所有数组元素的类型必须相同,例如:
arr=(20 56 "http://c.biancheng.net/shell/")
第三个元素就是一个“异类”,前面两个元素都是整数,而第三个元素是字符串。
Shell 数组的长度不是固定的,定义之后还可以增加元素。例如,对于上面的 nums 数组,它的长度是 6,使用下面的代码会在最后增加一个元素,使其长度扩展到 7:
nums[6]=88
此外,你也无需逐个元素地给数组赋值,下面的代码就是只给特定元素赋值:
ages=([3]=24 [5]=19 [10]=12)
以上代码就只给第 3、5、10 个元素赋值,所以数组长度是 3。
获取数组元素
获取数组元素的值,一般使用下面的格式:
${array_name[index]}
其中,array_name 是数组名,index 是下标。例如:
n=${nums[2]}
表示获取 nums 数组的第二个元素,然后赋值给变量 n。再如:
echo ${nums[3]}
表示输出 nums 数组的第 3 个元素。
使用@或*可以获取数组中的所有元素,例如:
${nums[*]}${nums[@]}
两者都可以得到 nums 数组的所有元素。
完整的演示:
#!/bin/bash
nums=(29 100 13 8 91 44)
echo ${nums[@]} #输出所有数组元素
nums[10]=66 #给第10个元素赋值(此时会增加数组长度)
echo ${nums[*]} #输出所有数组元素
echo ${nums[4]} #输出第4个元素
运行结果: 29 100 13 8 91 44 29 100 13 8 91 44 66 91
Shell获取数组长度¶
所谓数组长度,就是数组元素的个数。
利用@或*,可以将数组扩展成列表,然后使用#来获取数组元素的个数,格式如下:
${#array_name[@]} ${#array_name[*]}
其中 array_name 表示数组名。两种形式是等价的,选择其一即可。
如果某个元素是字符串,还可以通过指定下标的方式获得该元素的长度,如下所示:
${#arr[2]}
获取 arr 数组的第 2 个元素(假设它是字符串)的长度。
回忆字符串长度的获取
回想一下 Shell 是如何获取字符串长度的呢?其实和获取数组长度如出一辙,它的格式如下:
${#string_name}
string_name 是字符串名。
实例演示
下面我们通过实际代码来演示一下如何获取数组长度。
#!/bin/bash
nums=(29 100 13)
echo ${#nums[*]}
#向数组中添加元素
nums[10]="http://c.biancheng.net/shell/"
echo ${#nums[@]}
echo ${#nums[10]}
#删除数组元素
unset nums[1]
echo ${#nums[*]}
运行结果: 3 4 29 3
Shell数组拼接¶
所谓 Shell 数组拼接(数组合并),就是将两个数组连接成一个数组。
拼接数组的思路是:先利用@或*,将数组扩展成列表,然后再合并到一起。具体格式如下:
array_new=(${array1[@]} {array2[@]}) array_new=({array1[]} ${array2[]})
两种方式是等价的,选择其一即可。其中,array1 和 array2 是需要拼接的数组,array_new 是拼接后形成的新数组。
下面是完整的演示代码:
#!/bin/bash
array1=(23 56)
array2=(99 "http://c.biancheng.net/shell/")
array_new=(${array1[@]} ${array2[*]})
echo ${array_new[@]} #也可以写作 ${array_new[*]}
运行结果: 23 56 99 http://c.biancheng.net/shell/
Shell删除数组元素¶
在 Shell 中,使用 unset 关键字来删除数组元素,具体格式如下:
unset array_name[index]
其中,array_name 表示数组名,index 表示数组下标。
如果不写下标,而是写成下面的形式:
unset array_name
那么就是删除整个数组,所有元素都会消失。
下面我们通过具体的代码来演示:
#!/bin/bash
arr=(23 56 99 "http://c.biancheng.net/shell/")
unset arr[1]
echo ${arr[@]}
unset arr
echo ${arr[*]}
运行结果:
23 99 http://c.biancheng.net/shell/
注意最后的空行,它表示什么也没输出,因为数组被删除了,所以输出为空。
Shell关联数组¶
现在最新的 Bash Shell 已经支持关联数组了。关联数组使用字符串作为下标,而不是整数,这样可以做到见名知意。
关联数组也称为“键值对(key-value)”数组,键(key)也即字符串形式的数组下标,值(value)也即元素值。
例如,我们可以创建一个叫做 color 的关联数组,并用颜色名字作为下标。
declare -A colorcolor["red"]="#ff0000"color["green"]="#00ff00"color["blue"]="#0000ff"
也可以在定义的同时赋值:
declare -A color=(["red"]="#ff0000", ["green"]="#00ff00", ["blue"]="#0000ff")
不同于普通数组,关联数组必须使用带有-A选项的 declare 命令创建。关于 declare 命令的详细用法请访问:Shell declare和typeset命令:设置变量属性
访问关联数组元素
访问关联数组元素的方式几乎与普通数组相同,具体形式为:
array_name["index"]
例如:
color["white"]="#ffffff"color["black"]="#000000"
加上$()即可获取数组元素的值:
$(array_name["index"])
例如:
echo $(color["white"])white=$(color["black"])
获取所有元素的下标和值
使用下面的形式可以获得关联数组的所有元素值:
${array_name[@]} ${array_name[*]}
使用下面的形式可以获取关联数组的所有下标值:
${!array_name[@]} ${!array_name[*]}
获取关联数组长度
使用下面的形式可以获得关联数组的长度:
${#array_name[*]} ${#array_name[@]}
关联数组实例演示:
#!/bin/bash
declare -A color
color["red"]="#ff0000"
color["green"]="#00ff00"
color["blue"]="#0000ff"
color["white"]="#ffffff"
color["black"]="#000000"
#获取所有元素值
for value in ${color[*]}
do
echo $value
done
echo "****************"
#获取所有元素下标(键)
for key in ${!color[*]}
do
echo $key
done
echo "****************"
#列出所有键值对
for key in ${!color[@]}
do
echo "${key} -> ${color[$key]}"
done
运行结果: #ff0000 #0000ff #ffffff #000000 #00ff00
red blue white black green
red -> #ff0000 blue -> #0000ff white -> #ffffff black -> #000000 green -> #00ff00
Shell内置命令¶
所谓 Shell 内建命令,就是由 Bash 自身提供的命令,而不是文件系统中的某个可执行文件。
例如,用于进入或者切换目录的 cd 命令,虽然我们一直在使用它,但如果不加以注意很难意识到它与普通命令的性质是不一样的:该命令并不是某个外部文件,只要在 Shell 中你就一定可以运行这个命令。
可以使用 type 来确定一个命令是否是内建命令:
[root@localhost ~]# type cd cd is a Shell builtin [root@localhost ~]# type ifconfig ifconfig is /sbin/ifconfig
由此可见,cd 是一个 Shell 内建命令,而 ifconfig 是一个外部文件,它的位置是/sbin/ifconfig。
还记得系统变量 [PATH](http://c.biancheng.net/view/962.html) 吗?PATH 变量包含的目录中几乎聚集了系统中绝大多数的可执行命令,它们都是外部命令。
通常来说,内建命令会比外部命令执行得更快,执行外部命令时不但会触发磁盘 I/O,还需要 fork 出一个单独的进程来执行,执行完成后再退出。而执行内建命令相当于调用当前 Shell 进程的一个函数。
下表列出了 Bash Shell 中直接可用的内建命令。
| 命令 | 说明 |
|---|---|
| : | 扩展参数列表,执行重定向操作 |
| . | 读取并执行指定文件中的命令(在当前 shell 环境中) |
| alias | 为指定命令定义一个别名 |
| bg | 将作业以后台模式运行 |
| bind | 将键盘序列绑定到一个 readline 函数或宏 |
| break | 退出 for、while、select 或 until 循环 |
| builtin | 执行指定的 shell 内建命令 |
| caller | 返回活动子函数调用的上下文 |
| cd | 将当前目录切换为指定的目录 |
| command | 执行指定的命令,无需进行通常的 shell 查找 |
| compgen | 为指定单词生成可能的补全匹配 |
| complete | 显示指定的单词是如何补全的 |
| compopt | 修改指定单词的补全选项 |
| continue | 继续执行 for、while、select 或 until 循环的下一次迭代 |
| declare | 声明一个变量或变量类型。 |
| dirs | 显示当前存储目录的列表 |
| disown | 从进程作业表中刪除指定的作业 |
| echo | 将指定字符串输出到 STDOUT |
| enable | 启用或禁用指定的内建shell命令 |
| eval | 将指定的参数拼接成一个命令,然后执行该命令 |
| exec | 用指定命令替换 shell 进程 |
| exit | 强制 shell 以指定的退出状态码退出 |
| export | 设置子 shell 进程可用的变量 |
| fc | 从历史记录中选择命令列表 |
| fg | 将作业以前台模式运行 |
| getopts | 分析指定的位置参数 |
| hash | 查找并记住指定命令的全路径名 |
| help | 显示帮助文件 |
| history | 显示命令历史记录 |
| jobs | 列出活动作业 |
| kill | 向指定的进程 ID(PID) 发送一个系统信号 |
| let | 计算一个数学表达式中的每个参数 |
| local | 在函数中创建一个作用域受限的变量 |
| logout | 退出登录 shell |
| mapfile | 从 STDIN 读取数据行,并将其加入索引数组 |
| popd | 从目录栈中删除记录 |
| printf | 使用格式化字符串显示文本 |
| pushd | 向目录栈添加一个目录 |
| pwd | 显示当前工作目录的路径名 |
| read | 从 STDIN 读取一行数据并将其赋给一个变量 |
| readarray | 从 STDIN 读取数据行并将其放入索引数组 |
| readonly | 从 STDIN 读取一行数据并将其赋给一个不可修改的变量 |
| return | 强制函数以某个值退出,这个值可以被调用脚本提取 |
| set | 设置并显示环境变量的值和 shell 属性 |
| shift | 将位置参数依次向下降一个位置 |
| shopt | 打开/关闭控制 shell 可选行为的变量值 |
| source | 读取并执行指定文件中的命令(在当前 shell 环境中) |
| suspend | 暂停 Shell 的执行,直到收到一个 SIGCONT 信号 |
| test | 基于指定条件返回退出状态码 0 或 1 |
| times | 显示累计的用户和系统时间 |
| trap | 如果收到了指定的系统信号,执行指定的命令 |
| type | 显示指定的单词如果作为命令将会如何被解释 |
| typeset | 声明一个变量或变量类型。 |
| ulimit | 为系统用户设置指定的资源的上限 |
| umask | 为新建的文件和目录设置默认权限 |
| unalias | 刪除指定的别名 |
| unset | 刪除指定的环境变量或 shell 属性 |
| wait | 等待指定的进程完成,并返回退出状态码 |
接下来的几节我们将重点讲解几个常用的 Shell 内置命令。
Shell alias命令¶
alisa 用来给命令创建一个别名。若直接输入该命令且不带任何参数,则列出当前 Shell 进程中使用了哪些别名。现在你应该能理解类似ll这样的命令为什么与ls -l的效果是一样的吧。
下面让我们来看一下有哪些命令被默认创建了别名:
[mozhiyan@localhost ~]$ alias alias cp='cp -i' alias l.='ls -d .* --color=tty' alias ll='ls -l --color=tty' alias ls='ls --color=tty' alias mv='mv -i' alias rm='rm -i' alias which='alias | /usr/bin/which --tty-only --read-alias --show-dot --show-tilde'
你看,为了让我们使用方便,Shell 会给某些命令默认创建别名。
使用 alias 命令自定义别名
使用 alias 命令自定义别名的语法格式为:
alias new_name='command'
比如,一般的关机命令是shutdown-h now,写起来比较长,这时可以重新定义一个关机命令,以后就方便多了。
alias myShutdown='shutdown -h now'
再如,通过 date 命令可以获得当前的 UNIX 时间戳,具体写法为date +%s,如果你嫌弃它太长或者不容易记住,那可以给它定义一个别名。
alias timestamp='date +%s'
在《Shell命令替换》一节中,我们使用date +%s计算脚本的运行时间,现在学了 alias,就可以简化代码了。
#!/bin/bash
alias timestamp='date +%s'
begin=`timestamp`
sleep 20s
finish=$(timestamp)
difference=$((finish - begin))
echo "run time: ${difference}s"
运行脚本,20 秒后看到输出结果: run time: 20s
别名只是临时的
在代码中使用 alias 命令定义的别名只能在当前 Shell 进程中使用,在子进程和其它进程中都不能使用。当前 Shell 进程结束后,别名也随之消失。
要想让别名对所有的 Shell 进程都有效,就得把别名写入 Shell 配置文件。Shell 进程每次启动时都会执行配置文件中的代码做一些初始化工作,将别名放在配置文件中,那么每次启动进程都会定义这个别名。不知道如何修改配置文件的读者请猛击《Shell配置文件的加载》《编写自己的Shell配置文件》。
使用 unalias 命令删除别名
使用 unalias 内建命令可以删除当前 Shell 进程中的别名。unalias 有两种使用方法:
- 第一种用法是在命令后跟上某个命令的别名,用于删除指定的别名。
- 第二种用法是在命令后接
-a参数,删除当前 Shell 进程中所有的别名。
同样,这两种方法都是在当前 Shell 进程中生效的。要想永久删除配置文件中定义的别名,只能进入该文件手动删除。
# 删除 ll 别名 [mozhiyan@localhost ~]$ unalias ll # 再次运行该命令时,报“找不到该命令”的错误,说明该别名被删除了 [mozhiyan@localhost ~]$ ll -bash: ll: command not found
Shell echo命令¶
echo 是一个 Shell 内建命令,用来在终端输出字符串,并在最后默认加上换行符。请看下面的例子:
#!/bin/bash
name="Shell教程"
url="http://c.biancheng.net/shell/"
echo "读者,你好!" #直接输出字符串
echo $url #输出变量
echo "${name}的网址是:${url}" #双引号包围的字符串中可以解析变量
echo '${name}的网址是:${url}' #单引号包围的字符串中不能解析变量
运行结果:
读者,你好! http://c.biancheng.net/shell/ Shell教程的网址是:http://c.biancheng.net/shell/ {name}的网址是:{url}
不换行
echo 命令输出结束后默认会换行,如果不希望换行,可以加上-n参数,如下所示:
#!/bin/bash
name="Tom"
age=20
height=175
weight=62
echo -n "${name} is ${age} years old, "
echo -n "${height}cm in height "
echo "and ${weight}kg in weight."
echo "Thank you!"
运行结果:
Tom is 20 years old, 175cm in height and 62kg in weight. Thank you!
输出转义字符
默认情况下,echo 不会解析以反斜杠\开头的转义字符。比如,\n表示换行,echo 默认会将它作为普通字符对待。请看下面的例子:
[root@localhost ~]# echo "hello \nworld" hello \nworld
我们可以添加-e参数来让 echo 命令解析转义字符。例如:
[root@localhost ~]# echo -e "hello \nworld" hello world
\c 转义字符
有了-e参数,我们也可以使用转义字符\c来强制 echo 命令不换行了。请看下面的例子:
#!/bin/bash
name="Tom"
age=20
height=175
weight=62
echo -e "${name} is ${age} years old, \c"
echo -e "${height}cm in height \c"
echo "and ${weight}kg in weight."
echo "Thank you!"
运行结果:
Tom is 20 years old, 175cm in height and 62kg in weight. Thank you!
Shell read命令¶
ead 是 Shell 内置命令,用来从标准输入中读取数据并赋值给变量。如果没有进行重定向,默认就是从键盘读取用户输入的数据;如果进行了重定向,那么可以从文件中读取数据。
后续我们会在《Linux Shell重定向》一节中深入讲解重定向的概念,不了解的读者可以不用理会,暂时就认为:read 命令就是从键盘读取数据。
read 命令的用法为:
read [-options] [variables]
options表示选项,如下表所示;variables表示用来存储数据的变量,可以有一个,也可以有多个。
options和variables都是可选的,如果没有提供变量名,那么读取的数据将存放到环境变量 REPLY 中。
| 选项 | 说明 |
|---|---|
| -a array | 把读取的数据赋值给数组 array,从下标 0 开始。 |
| -d delimiter | 用字符串 delimiter 指定读取结束的位置,而不是一个换行符(读取到的数据不包括 delimiter)。 |
| -e | 在获取用户输入的时候,对功能键进行编码转换,不会直接显式功能键对应的字符。 |
| -n num | 读取 num 个字符,而不是整行字符。 |
| -p prompt | 显示提示信息,提示内容为 prompt。 |
| -r | 原样读取(Raw mode),不把反斜杠字符解释为转义字符。 |
| -s | 静默模式(Silent mode),不会在屏幕上显示输入的字符。当输入密码和其它确认信息的时候,这是很有必要的。 |
| -t seconds | 设置超时时间,单位为秒。如果用户没有在指定时间内输入完成,那么 read 将会返回一个非 0 的退出状态,表示读取失败。 |
| -u fd | 使用文件描述符 fd 作为输入源,而不是标准输入,类似于重定向。 |
【实例1】使用 read 命令给多个变量赋值。
#!/bin/bash
read -p "Enter some information > " name url age
echo "网站名字:$name"
echo "网址:$url"
echo "年龄:$age"
运行结果: Enter some information > C语言中文网 http://c.biancheng.net 7↙ 网站名字:C语言中文网 网址:http://c.biancheng.net 年龄:7
注意,必须在一行内输入所有的值,不能换行,否则只能给第一个变量赋值,后续变量都会赋值失败。
本例还使用了-p选项,该选项会用一段文本来提示用户输入。
【示例2】只读取一个字符。
#!/bin/bash
read -n 1 -p "Enter a char > " char
printf "\n" #换行
echo $char
运行结果: Enter a char > 1 1
-n 1表示只读取一个字符。运行脚本后,只要用户输入一个字符,立即读取结束,不用等待用户按下回车键。
printf "\n"语句用来达到换行的效果,否则 echo 的输出结果会和用户输入的内容位于同一行,不容易区分。
【实例3】在指定时间内输入密码。
#!/bin/bash
if
read -t 20 -sp "Enter password in 20 seconds(once) > " pass1 && printf "\n" && #第一次输入密码
read -t 20 -sp "Enter password in 20 seconds(again)> " pass2 && printf "\n" && #第二次输入密码
[ $pass1 == $pass2 ] #判断两次输入的密码是否相等
then
echo "Valid password"
else
echo "Invalid password"
fi
这段代码中,我们使用&&组合了多个命令,这些命令会依次执行,并且从整体上作为 if 语句的判断条件,只要其中一个命令执行失败(退出状态为非 0 值),整个判断条件就失败了,后续的命令也就没有必要执行了。
如果两次输入密码相同,运行结果为: Enter password in 20 seconds(once) > Enter password in 20 seconds(again)> Valid password
如果两次输入密码不同,运行结果为: Enter password in 20 seconds(once) > Enter password in 20 seconds(again)> Invalid password
如果第一次输入超时,运行结果为: Enter password in 20 seconds(once) > Invalid password
如果第二次输入超时,运行结果为: Enter password in 20 seconds(once) > Enter password in 20 seconds(again)> Invalid password
Shell exit命令¶
exit 是一个 Shell 内置命令,用来退出当前 Shell 进程,并返回一个退出状态;使用$?可以接收这个退出状态,这一点已在《Shell $?》中进行了讲解。
exit 命令可以接受一个整数值作为参数,代表退出状态。如果不指定,默认状态值是 0。
一般情况下,退出状态为 0 表示成功,退出状态为非 0 表示执行失败(出错)了。
exit 退出状态只能是一个介于 0~255 之间的整数,其中只有 0 表示成功,其它值都表示失败。
Shell 进程执行出错时,可以根据退出状态来判断具体出现了什么错误,比如打开一个文件时,我们可以指定 1 表示文件不存在,2 表示文件没有读取权限,3 表示文件类型不对。
编写下面的脚本,并命名为 test.sh:
#!/bin/bash
echo "befor exit"
exit 8
echo "after exit"
运行该脚本:
[mozhiyan@localhost ~]$ bash ./test.sh befor exit
可以看到,"after exit"并没有输出,这说明遇到 exit 命令后,test.sh 执行就结束了。
注意,exit 表示退出当前 Shell 进程,我们必须在新进程中运行 test.sh,否则当前 Shell 会话(终端窗口)会被关闭,我们就无法看到输出结果了。
我们可以紧接着使用$?来获取 test.sh 的退出状态:
[mozhiyan@localhost ~]$ echo $? 8
Shell declare命令¶
declare 和 typeset 都是 Shell 内建命令,它们的用法相同,都用来设置变量的属性。不过 typeset 已经被弃用了,建议使用 declare 代替。
declare 命令的用法如下所示:
declare [±] [aAfFgilprtux] [变量名=变量值]
其中,-表示设置属性,+表示取消属性,aAfFgilprtux都是具体的选项,它们的含义如下表所示:
| 选项 | 含义 |
|---|---|
| -f [name] | 列出之前由用户在脚本中定义的函数名称和函数体。 |
| -F [name] | 仅列出自定义函数名称。 |
| -g name | 在 Shell 函数内部创建全局变量。 |
| -p [name] | 显示指定变量的属性和值。 |
| -a name | 声明变量为普通数组。 |
| -A name | 声明变量为关联数组(支持索引下标为字符串)。 |
| -i name | 将变量定义为整数型。 |
| -r name[=value] | 将变量定义为只读(不可修改和删除),等价于 readonly name。 |
| -x name[=value] | 将变量设置为环境变量,等价于 export name[=value]。 |
【实例1】将变量声明为整数并进行计算。
#!/bin/bash
declare -i m n ret #将多个变量声明为整数
m=10
n=30
ret=$m+$n
echo $ret
运行结果: 40
【实例2】将变量定义为只读变量。
[c.biancheng.net]$ declare -r n=10
[c.biancheng.net]$ n=20
bash: n: 只读变量
[c.biancheng.net]$ echo $n
10
【实例3】显示变量的属性和值。
[c.biancheng.net]$ declare -r n=10
[c.biancheng.net]$ declare -p n
declare -r n="10"
Shell数学计算¶
如果要执行算术运算(数学计算),就离不开各种运算符号,和其他编程语言类似,Shell 也有很多算术运算符,下面就给大家介绍一下常见的 Shell 算术运算符,如下表所示。
| 算术运算符 | 说明/含义 |
|---|---|
| +、- | 加法(或正号)、减法(或负号) |
| *、/、% | 乘法、除法、取余(取模) |
| ** | 幂运算 |
| ++、-- | 自增和自减,可以放在变量的前面也可以放在变量的后面 |
| !、&&、|| | 逻辑非(取反)、逻辑与(and)、逻辑或(or) |
| <、<=、>、>= | 比较符号(小于、小于等于、大于、大于等于) |
| ==、!=、= | 比较符号(相等、不相等;对于字符串,= 也可以表示相当于) |
| <<、>> | 向左移位、向右移位 |
| ~、|、 &、^ | 按位取反、按位或、按位与、按位异或 |
| =、+=、-=、*=、/=、%= | 赋值运算符,例如 a+=1 相当于 a=a+1,a-=1 相当于 a=a-1 |
但是,Shell 和其它编程语言不同,Shell 不能直接进行算数运算,必须使用数学计算命令,这让初学者感觉很困惑,也让有经验的程序员感觉很奇葩。
下面我们先来看一个反面的例子:
[c.biancheng.net]$ echo 2+8 2+8 [c.biancheng.net]$ a=23 [c.biancheng.net]$ b=a+55 [c.biancheng.net] echo b 23+55 [c.biancheng.net] b=90 [c.biancheng.net]$ c=a+b [c.biancheng.net]$ echo $c 23+90
从上面的运算结果可以看出,默认情况下,Shell 不会直接进行算术运算,而是把+两边的数据(数值或者变量)当做字符串,把+当做字符串连接符,最终的结果是把两个字符串拼接在一起形成一个新的字符串。
这是因为,在 Bash Shell 中,如果不特别指明,每一个变量的值都是字符串,无论你给变量赋值时有没有使用引号,值都会以字符串的形式存储。
换句话说,Bash shell 在默认情况下不会区分变量类型,即使你将整数和小数赋值给变量,它们也会被视为字符串,这一点和大部分的编程语言不同。
这一点我们已在《Shell变量》中提到,读者可以猛击链接回忆。
数学计算命令
要想让数学计算发挥作用,必须使用数学计算命令,Shell 中常用的数学计算命令如下表所示。
| 运算操作符/运算命令 | 说明 |
|---|---|
| (( )) | 用于整数运算,效率很高,推荐使用。 |
| let | 用于整数运算,和 (()) 类似。 |
| [$] | 用于整数运算,不如 (()) 灵活。 |
| expr | 可用于整数运算,也可以处理字符串。比较麻烦,需要注意各种细节,不推荐使用。 |
| bc | Linux下的一个计算器程序,可以处理整数和小数。Shell 本身只支持整数运算,想计算小数就得使用 bc 这个外部的计算器。 |
| declare -i | 将变量定义为整数,然后再进行数学运算时就不会被当做字符串了。功能有限,仅支持最基本的数学运算(加减乘除和取余),不支持逻辑运算、自增自减等,所以在实际开发中很少使用。 |
如果大家时间有限,只学习 (()) 和 bc 即可,不用学习其它的了:(()) 可以用于整数计算,bc 可以小数计算。
在接下来的章节中,我们将逐一为大家讲解 Shell 中的各种运算符号及运算命令。
shell双括号用法¶
双小括号 (( )) 是 Bash Shell 中专门用来进行整数运算的命令,它的效率很高,写法灵活,是企业运维中常用的运算命令。
注意:(( )) 只能进行整数运算,不能对小数(浮点数)或者字符串进行运算。后续讲到的 bc 命令可以用于小数运算。
Shell (( )) 的用法
双小括号 (( )) 的语法格式为:
((表达式))
通俗地讲,就是将数学运算表达式放在((和))之间。
表达式可以只有一个,也可以有多个,多个表达式之间以逗号,分隔。对于多个表达式的情况,以最后一个表达式的值作为整个 (( )) 命令的执行结果。
可以使用$获取 (( )) 命令的结果,这和使用$获得变量值是类似的。
| 运算操作符/运算命令 | 说明 |
|---|---|
| ((a=10+66) ((b=a-15)) ((c=a+b)) | 这种写法可以在计算完成后给变量赋值。以 ((b=a-15)) 为例,即将 a-15 的运算结果赋值给变量 c。 注意,使用变量时不用加$前缀,(( )) 会自动解析变量名。 |
| a=((10+66) b=((a-15)) c=$((a+b)) | 可以在 (( )) 前面加上$符号获取 (( )) 命令的执行结果,也即获取整个表达式的值。以 c=$((a+b)) 为例,即将 a+b 这个表达式的运算结果赋值给变量 c。 注意,类似 c=((a+b)) 这样的写法是错误的,不加$就不能取得表达式的结果。 |
| ((a>7 && b==c)) | (( )) 也可以进行逻辑运算,在 if 语句中常会使用逻辑运算。 |
| echo $((a+10)) | 需要立即输出表达式的运算结果时,可以在 (( )) 前面加$符号。 |
| ((a=3+5, b=a+10)) | 对多个表达式同时进行计算。 |
在 (( )) 中使用变量无需加上$前缀,(( )) 会自动解析变量名,这使得代码更加简洁,也符合程序员的书写习惯。
Shell (( )) 实例演示
【实例1】利用 (( )) 进行简单的数值计算。
[c.biancheng.net]$ echo $((1+1))
2
[c.biancheng.net]$ echo $((6-3))
3
[c.biancheng.net]$ i=5
[c.biancheng.net]$ ((i=i*2)) #可以简写为 ((i*=2))。
[c.biancheng.net]$ echo $i #使用 echo 输出变量结果时要加 $。
10
【实例2】用 (( )) 进行稍微复杂一些的综合算术运算。
[c.biancheng.net]$ ((a=1+2**3-4%3))
[c.biancheng.net]$ echo $a
8
[c.biancheng.net]$ b=$((1+2**3-4%3)) #运算后将结果赋值给变量,变量放在了括号的外面。
[c.biancheng.net]$ echo $b
8
[c.biancheng.net]$ echo $((1+2**3-4%3)) #也可以直接将表达式的结果输出,注意不要丢掉 $ 符号。
8
[c.biancheng.net]$ a=$((100*(100+1)/2)) #利用公式计算1+2+3+...+100的和。
[c.biancheng.net]$ echo $a
5050
[c.biancheng.net]$ echo $((100*(100+1)/2)) #也可以直接输出表达式的结果。
5050
【实例3】利用 (( )) 进行逻辑运算。
[c.biancheng.net]$ echo $((3<8)) #3<8 的结果是成立的,因此,输出了 1,1 表示真
1
[c.biancheng.net]$ echo $((8<3)) #8<3 的结果是不成立的,因此,输出了 0,0 表示假。
0
[c.biancheng.net]$ echo $((8==8)) #判断是否相等。
1
[c.biancheng.net]$ if ((8>7&&5==5))
> then
> echo yes
> fi
yes
最后是一个简单的 if 语句的格式,它的意思是,如果 8>7 成立,并且 5==5 成立,那么输出 yes。显然,这两个条件都是成立的,所以输出了 yes。
【实例4】利用 (( )) 进行自增(++)和自减(--)运算。
[c.biancheng.net]$ a=10
[c.biancheng.net]$ echo $((a++)) #如果++在a的后面,那么在输出整个表达式时,会输出a的值,因为a为10,所以表达式的值为10。
10
[c.biancheng.net]$ echo $a #执行上面的表达式后,因为有a++,因此a会自增1,因此输出a的值为11。
11
[c.biancheng.net]$ a=11
[c.biancheng.net]$ echo $((a--)) #如果--在a的后面,那么在输出整个表达式时,会输出a的值,因为a为11,所以表达式的值的为11。
11
[c.biancheng.net]$ echo $a #执行上面的表达式后,因为有a--,因此a会自动减1,因此a为10。
10
[c.biancheng.net]$ a=10
[c.biancheng.net]$ echo $((--a)) #如果--在a的前面,那么在输出整个表达式时,先进行自增或自减计算,因为a为10,且要自减,所以表达式的值为9。
9
[c.biancheng.net]$ echo $a #执行上面的表达式后,a自减1,因此a为9。
9
[c.biancheng.net]$ echo $((++a)) #如果++在a的前面,输出整个表达式时,先进行自增或自减计算,因为a为9,且要自增1,所以输出10。
10
[c.biancheng.net]$ echo $a #执行上面的表达式后,a自增1,因此a为10。
10
本教程假设读者具备基本的编程能力,相信读者对于前自增(前自减)和后自增(后自减)的区别也非常清楚,这里就不再赘述,只进行简单的说明:
- 执行 echo $((a++)) 和 echo $((a--)) 命令输出整个表达式时,输出的值即为 a 的值,表达式执行完毕后,会再对 a 进行 ++、-- 的运算;
- 而执行 echo $((++a)) 和 echo $((--a)) 命令输出整个表达式时,会先对 a 进行 ++、-- 的运算,然后再输出表达式的值,即为 a 运算后的值。
【实例5】利用 (( )) 同时对多个表达式进行计算。
[c.biancheng.net]$ ((a=3+5, b=a+10)) #先计算第一个表达式,再计算第二个表达式
[c.biancheng.net]$ echo $a $b
8 18
[c.biancheng.net]$ c=$((4+8, a+b)) #以最后一个表达式的结果作为整个(())命令的执行结果
[c.biancheng.net]$ echo $c
26
Shell let命令¶
let 命令和双小括号 (( )) 的用法是类似的,它们都是用来对整数进行运算,读者已经学习了《Shell (())》,再学习 let 命令就相当简单了。
注意:和双小括号 (( )) 一样,let 命令也只能进行整数运算,不能对小数(浮点数)或者字符串进行运算。
Shell let 命令的语法格式为:
let 表达式
或者
let "表达式"
或者
let '表达式'
它们都等价于((表达式))。
当表达式中含有 Shell 特殊字符(例如 |)时,需要用双引号" "或者单引号' '将表达式包围起来。
和 (( )) 类似,let 命令也支持一次性计算多个表达式,并且以最后一个表达式的值作为整个 let 命令的执行结果。但是,对于多个表达式之间的分隔符,let 和 (( )) 是有区别的:
- let 命令以空格来分隔多个表达式;
- (( )) 以逗号
,来分隔多个表达式。
另外还要注意,对于类似let x+y这样的写法,Shell 虽然计算了 x+y 的值,但却将结果丢弃;若不想这样,可以使用let sum=x+y将 x+y 的结果保存在变量 sum 中。
这种情况下 (( )) 显然更加灵活,可以使用$((x+y))来获取 x+y 的结果。请看下面的例子:
[c.biancheng.net]$ a=10 b=20
[c.biancheng.net]$ echo $((a+b))
30
[c.biancheng.net]$ echo let a+b #错误,echo会把 let a+b作为一个字符串输出
let a+b
Shell let 命令实例演示
【实例1】给变量 i 加 8:
[c.biancheng.net]$ i=2
[c.biancheng.net]$ let i+=8
[c.biancheng.net]$ echo $i
10
let i+=8 等同于 ((i+=8)),但后者效率更高。
【实例2】let 后面可以跟多个表达式。
[c.biancheng.net]$ a=10 b=35
[c.biancheng.net]$ let a+=6 c=a+b #多个表达式以空格为分隔
[c.biancheng.net]$ echo $a $c
16 51
shell整数数学运算¶
和 (())、let 命令类似,$[] 也只能进行整数运算。
Shell $[] 的用法如下:
$[表达式]
$[] 会对表达式进行计算,并取得计算结果。如果表达式中包含了变量,那么你可以加$,也可以不加。
Shell $[] 举例:
[c.biancheng.net]$ echo $[3*5] #直接输出结算结果
15
[c.biancheng.net]$ echo $[(3+4)*5] #使用()
35
[c.biancheng.net]$ n=6
[c.biancheng.net]$ m=$[n*2] #将计算结果赋值给变量
[c.biancheng.net]$ echo $[m+n]
18
[c.biancheng.net]$ echo $[$m*$n] #在变量前边加$也是可以的
72
[c.biancheng.net]$ echo $[4*(m+n)]
72
需要注意的是,不能单独使用 $[],必须能够接收 $[] 的计算结果。例如,下面的用法是错误的:
[c.biancheng.net]$ $[3+4]
bash: 7: 未找到命令...
[c.biancheng.net]$ $[m+3]
bash: 15: 未找到命令...
Shell expr命令¶
expr 是 evaluate expressions 的缩写,译为“表达式求值”。Shell expr 是一个功能强大,并且比较复杂的命令,它除了可以实现整数计算,还可以结合一些选项对字符串进行处理,例如计算字符串长度、字符串比较、字符串匹配、字符串提取等。
本节只讲解 expr 在整数计算方面的应用,并不涉及字符串处理,有兴趣的读者请自行研究。
Shell expr 对于整数计算的用法为:
expr 表达式
expr 对表达式的格式有几点特殊的要求:
- 出现在
表达式中的运算符、数字、变量和小括号的左右两边至少要有一个空格,否则会报错。 - 有些特殊符号必须用反斜杠
\进行转义(屏蔽其特殊含义),比如乘号*和小括号(),如果不用\转义,那么 Shell 会把它们误解为正则表达式中的符号(*对应通配符,()对应分组)。 - 使用变量时要加
$前缀。
【实例1】expr 整数计算简单举例:
[c.biancheng.net]$ expr 2 +3 #错误:加号和 3 之前没有空格
expr: 语法错误
[c.biancheng.net]$ expr 2 + 3 #这样才是正确的
5
[c.biancheng.net]$ expr 4 * 5 #错误:乘号没有转义
expr: 语法错误
[c.biancheng.net]$ expr 4 \* 5 #使用 \ 转义后才是正确的
20
[c.biancheng.net]$ expr ( 2 + 3 ) \* 4 #小括号也需要转义
bash: 未预期的符号 `2' 附近有语法错误
[c.biancheng.net]$ expr \( 2 + 3 \) \* 4 #使用 \ 转义后才是正确的
20
[c.biancheng.net]$ n=3
[c.biancheng.net]$ expr n + 2 #使用变量时要加 $
expr: 非整数参数
[c.biancheng.net]$ expr $n + 2 #加上 $ 才是正确的
5
[c.biancheng.net]$ m=7
[c.biancheng.net]$ expr $m \* \( $n + 5 \)
56
以上是直接使用 expr 命令,计算结果会直接输出,如果你希望将计算结果赋值给变量,那么需要将整个表达式用反引号````(位于 Tab 键的上方)包围起来,请看下面的例子。
【实例2】将 expr 的计算结果赋值给变量:
[c.biancheng.net]$ m=5
[c.biancheng.net]$ n=`expr $m + 10`
[c.biancheng.net]$ echo $n
15
你看,使用 expr 进行数学计算是多么的麻烦呀,需要注意各种细节,我奉劝大家还是省省心,老老实实用 (())、let 或者 $[] 吧。
Shell变量声明¶
在《Shell declare命令》一节中,我们已经讲解了 declare 命令的各种选项,为了让 Shell 进行整数运算,本节我们重点讲解-i选项。
默认情况下,Shell 中每一个变量的值都是字符串(不了解的读者请猛击《Shell变量》),即使你给变量赋值一个数字,它其实也是字符串,所以在进行数学计算时会出错。
使用 declare 命令的-i选项可以将一个变量声明为整数类型,这样在进行数学计算时就不会作为字符串处理了,请看下面的例子:
#!/bin/bash
declare -i m n ret
m=10
n=30
ret=$m+$n
echo $ret
ret=$n/$m
echo $ret
运行结果: 40 3
除了将 m、n 定义为整数,还必须将 ret 定义为整数,如果不这样做,在执行ret=$m+$n和ret=$n/$m时,Shell 依然会将 m、n 视为字符串。
此外,你也不能写类似echo $m+$n这样的语句,这种情况下 m、n 也会被视为字符串。
总之,除了将参与运算的变量定义为整数,还得将承载结果的变量定义为整数,而且只能用整数类型的变量来承载运算结果,不能直接使用 echo 输出。
和 (())、let、$[] 不同,declare -i的功能非常有限,仅支持最基本的数学运算(加减乘除和取余),不支持逻辑运算(比较运算、与运算、或运算、非运算),所以在实际开发中很少使用。
Shell if判断语句¶
和其它编程语言类似,Shell 也支持选择结构,并且有两种形式,分别是 if else 语句和 case in 语句。本节我们先介绍 if else 语句,case in 语句将会在《Shell case in》中介绍。
如果你已经熟悉了C语言、Java、JavaScript 等其它编程语言,那么你可能会觉得 Shell 中的 if else 语句有点奇怪。
if 语句
最简单的用法就是只使用 if 语句,它的语法格式为:
if condition then statement(s) fi
condition是判断条件,如果 condition 成立(返回“真”),那么 then 后边的语句将会被执行;如果 condition 不成立(返回“假”),那么不会执行任何语句。
从本质上讲,if 检测的是命令的退出状态,我们将在下节《Shell退出状态》中深入讲解。
注意,最后必须以fi来闭合,fi 就是 if 倒过来拼写。也正是有了 fi 来结尾,所以即使有多条语句也不需要用{ }包围起来。
如果你喜欢,也可以将 then 和 if 写在一行:
if condition; then statement(s) fi
请注意 condition 后边的分号;,当 if 和 then 位于同一行的时候,这个分号是必须的,否则会有语法错误。
实例1
下面的例子使用 if 语句来比较两个数字的大小:
#!/bin/bashread aread bif (( $a == $b ))then echo "a和b相等"fi
运行结果: 84↙ 84↙ a和b相等
在《Shell (())》一节中我们讲到,(())是一种数学计算命令,它除了可以进行最基本的加减乘除运算,还可以进行大于、小于、等于等关系运算,以及与、或、非逻辑运算。当 a 和 b 相等时,(( $a == $b ))判断条件成立,进入 if,执行 then 后边的 echo 语句。
实例2
在判断条件中也可以使用逻辑运算符,例如:
#!/bin/bashread ageread iqif (( $age > 18 && $iq < 60 ))then echo "你都成年了,智商怎么还不及格!" echo "来C语言中文网(http://c.biancheng.net/)学习编程吧,能迅速提高你的智商。"fi
运行结果: 20↙ 56↙ 你都成年了,智商怎么还不及格! 来C语言中文网(http://c.biancheng.net/)学习编程吧,能迅速提高你的智商。
&&就是逻辑“与”运算符,只有当&&两侧的判断条件都为“真”时,整个判断条件才为“真”。
熟悉其他编程语言的读者请注意,即使 then 后边有多条语句,也不需要用{ }包围起来,因为有 fi 收尾呢。
if else 语句
如果有两个分支,就可以使用 if else 语句,它的格式为:
if condition then statement1 else statement2 fi
如果 condition 成立,那么 then 后边的 statement1 语句将会被执行;否则,执行 else 后边的 statement2 语句。
举个例子:
#!/bin/bash
read a
read b
if (( $a == $b ))
then
echo "a和b相等"
else
echo "a和b不相等,输入错误"
fi
运行结果: 10↙ 20↙ a 和 b 不相等,输入错误
从运行结果可以看出,a 和 b 不相等,判断条件不成立,所以执行了 else 后边的语句。
if elif else 语句
Shell 支持任意数目的分支,当分支比较多时,可以使用 if elif else 结构,它的格式为:
if condition1 then statement1 elif condition2 then statement2 elif condition3 then statement3 …… else statementn fi
注意,if 和 elif 后边都得跟着 then。
整条语句的执行逻辑为:
- 如果 condition1 成立,那么就执行 if 后边的 statement1;如果 condition1 不成立,那么继续执行 elif,判断 condition2。
- 如果 condition2 成立,那么就执行 statement2;如果 condition2 不成立,那么继续执行后边的 elif,判断 condition3。
- 如果 condition3 成立,那么就执行 statement3;如果 condition3 不成立,那么继续执行后边的 elif。
- 如果所有的 if 和 elif 判断都不成立,就进入最后的 else,执行 statementn。
举个例子,输入年龄,输出对应的人生阶段:
#!/bin/bash
read age
if (( $age <= 2 )); then
echo "婴儿"
elif (( $age >= 3 && $age <= 8 )); then
echo "幼儿"
elif (( $age >= 9 && $age <= 17 )); then
echo "少年"
elif (( $age >= 18 && $age <=25 )); then
echo "成年"
elif (( $age >= 26 && $age <= 40 )); then
echo "青年"
elif (( $age >= 41 && $age <= 60 )); then
echo "中年"
else
echo "老年"
fi
运行结果1: 19 成年
运行结果2: 100 老年
再举一个例子,输入一个整数,输出该整数对应的星期几的英文表示:
#!/bin/bash
printf "Input integer number: "
read num
if ((num==1)); then
echo "Monday"
elif ((num==2)); then
echo "Tuesday"
elif ((num==3)); then
echo "Wednesday"
elif ((num==4)); then
echo "Thursday"
elif ((num==5)); then
echo "Friday"
elif ((num==6)); then
echo "Saturday"
elif ((num==7)); then
echo "Sunday"
else
echo "error"
fi
运行结果1: Input integer number: 4 Thursday
运行结果2: Input integer number: 9 error
Shell退出状态¶
每一条 Shell 命令,不管是 Bash 内置命令(例如 cd、echo),还是外部的 Linux 命令(例如 ls、awk),还是自定义的 Shell 函数,当它退出(运行结束)时,都会返回一个比较小的整数值给调用(使用)它的程序,这就是命令的**退出状态(exit statu)**。
很多 Linux 命令其实就是一个C语言程序,熟悉C语言的读者都知道,main() 函数的最后都有一个
return 0,如果程序想在中间退出,还可以使用exit 0,这其实就是C语言程序的退出状态。当有其它程序调用这个程序时,就可以捕获这个退出状态。
if 语句的判断条件,从本质上讲,判断的就是命令的退出状态。
按照惯例来说,退出状态为 0 表示“成功”;也就是说,程序执行完成并且没有遇到任何问题。除 0 以外的其它任何退出状态都为“失败”。
之所以说这是“惯例”而非“规定”,是因为也会有例外,比如 diff 命令用来比较两个文件的不同,对于“没有差别”的文件返回 0,对于“找到差别”的文件返回 1,对无效文件名返回 2。
有编程经验的读者请注意,Shell 的这个部分与你所熟悉的其它编程语言正好相反:在C语言、C++、Java、Python 中,0 表示“假”,其它值表示“真”。
在 Shell 中,有多种方式取得命令的退出状态,其中 $? 是最常见的一种。上节《Shell if else》中使用了 (()) 进行数学计算,我们不妨来看一下它的退出状态。请看下面的代码:
#!/bin/bashread aread b(( $a == $b ));echo "退出状态:"$?
运行结果1: 26 26 退出状态:0
运行结果2: 17 39 退出状态:1
退出状态和逻辑运算符的组合
Shell if 语句的一个神奇之处是允许我们使用逻辑运算符将多个退出状态组合起来,这样就可以一次判断多个条件了。
| 运算符 | 使用格式 | 说明 |
|---|---|---|
| && | expression1 && expression2 | 逻辑与运算符,当 expression1 和 expression2 同时成立时,整个表达式才成立。 如果检测到 expression1 的退出状态为 0,就不会再检测 expression2 了,因为不管 expression2 的退出状态是什么,整个表达式必然都是不成立的,检测了也是多此一举。 |
| || | expression1 || expression2 | 逻辑或运算符,expression1 和 expression2 两个表达式中只要有一个成立,整个表达式就成立。 如果检测到 expression1 的退出状态为 1,就不会再检测 expression2 了,因为不管 expression2 的退出状态是什么,整个表达式必然都是成立的,检测了也是多此一举。 |
| ! | !expression | 逻辑非运算符,相当于“取反”的效果。如果 expression 成立,那么整个表达式就不成立;如果 expression 不成立,那么整个表达式就成立。 |
【实例】将用户输入的 URL 写入到文件中。
#!/bin/bash
read filename
read url
if test -w $filename && test -n $url
then
echo $url > $filename
echo "写入成功"
else
echo "写入失败"
fi
在 Shell 脚本文件所在的目录新建一个文本文件并命名为 urls.txt,然后运行 Shell 脚本,运行结果为: urls.txt↙ http://c.biancheng.net/shell/↙ 写入成功
test 是 Shell 内置命令,可以对文件或者字符串进行检测,其中,-w选项用来检测文件是否存在并且可写,-n选项用来检测字符串是否非空。下节《Shell test》中将会详细讲解。
>表示重定向,默认情况下,echo 向控制台输出,这里我们将输出结果重定向到文件。
Shell test命令¶
Shell 中括号详解¶
[[ ]]是 Shell 内置关键字,它和 test 命令类似,也用来检测某个条件是否成立。
test 能做到的,[[ ]] 也能做到,而且 [[ ]] 做的更好;test 做不到的,[[ ]] 还能做到。可以认为 [[ ]] 是 test 的升级版,对细节进行了优化,并且扩展了一些功能。
[[ ]] 的用法为:
[[ expression ]]
当 [[ ]] 判断 expression 成立时,退出状态为 0,否则为非 0 值。注意[[ ]]和expression之间的空格,这两个空格是必须的,否则会导致语法错误。
[[ ]] 不需要注意某些细枝末节
[[ ]] 是 Shell 内置关键字,不是命令,在使用时没有给函数传递参数的过程,所以 test 命令的某些注意事项在 [[ ]] 中就不存在了,具体包括:
- 不需要把变量名用双引号
""包围起来,即使变量是空值,也不会出错。 - 不需要、也不能对 >、< 进行转义,转义后会出错。
请看下面的演示代码:
#!/bin/bash
read str1
read str2
if [[ -z $str1 ]] || [[ -z $str2 ]] #不需要对变量名加双引号
then
echo "字符串不能为空"
elif [[ $str1 < $str2 ]] #不需要也不能对 < 进行转义
then
echo "str1 < str2"
else
echo "str1 >= str2"
fi
运行结果: http://c.biancheng.net/shell/ http://data.biancheng.net/ str1 < str2
[[ ]] 支持逻辑运算符
对多个表达式进行逻辑运算时,可以使用逻辑运算符将多个 test 命令连接起来,例如:
[ -z "str1" ] || [ -z "str2" ]
你也可以借助选项把多个表达式写在一个 test 命令中,例如:
[ -z "str1" -o -z "str2" ]
但是,这两种写法都有点“别扭”,完美的写法是在一个命令中使用逻辑运算符将多个表达式连接起来。我们的这个愿望在 [[ ]] 中实现了,[[ ]] 支持 &&、|| 和 ! 三种逻辑运算符。
使用 [[ ]] 对上面的语句进行改进:
[[ -z $str1 || -z $str2 ]]
这种写法就比较简洁漂亮了。
注意,[[ ]] 剔除了 test 命令的-o和-a选项,你只能使用 || 和 &&。这意味着,你不能写成下面的形式:
[[ -z $str1 -o -z $str2 ]]
当然,使用逻辑运算符将多个 [[ ]] 连接起来依然是可以的,因为这是 Shell 本身提供的功能,跟 [[ ]] 或者 test 没有关系,如下所示:
[[ -z $str1 ]] || [[ -z $str2 ]]
| test 或 [] | [[ ]] | ||
|---|---|---|---|
| [ -z "str1" ] \|\| [ -z "str2" ] | √ | [[ -z $str1 ]] || [[ -z $str2 ]] | √ |
| [ -z "str1" -o -z "str2" ] | √ | [[ -z $str1 -o -z $str2 ]] | × |
| [ -z $str1 || -z $str2 ] | × | [[ -z $str1 || -z $str2 ]] | √ |
[[ ]] 支持正则表达式
在 Shell [[ ]] 中,可以使用=~来检测字符串是否符合某个正则表达式,它的用法为:
[[ str =~ regex ]]
str 表示字符串,regex 表示正则表达式。
下面的代码检测一个字符串是否是手机号:
#!/bin/bash
read tel
if [[ $tel =~ ^1[0-9]{10}$ ]]
then
echo "你输入的是手机号码"
else
echo "你输入的不是手机号码"
fi
运行结果1: 13203451100 你输入的是手机号码
运行结果2: 132034511009 你输入的不是手机号码
对^1[0-9]{10}$的说明:
^匹配字符串的开头(一个位置);[0-9]{10}匹配连续的十个数字;$匹配字符串的末尾(一个位置)。
本文并不打算讲解正则表达式的语法,不了解的读者请猛击《正则表达式30分钟入门教程》。
总结
有了 [[ ]],你还有什么理由使用 test 或者 [ ],[[ ]] 完全可以替代之,而且更加方便,更加强大。
但是 [[ ]] 对数字的比较仍然不友好,所以我建议,以后大家使用 if 判断条件时,用 (()) 来处理整型数字,用 [[ ]] 来处理字符串或者文件。
Shell case条件语句¶
和其它编程语言类似,Shell 也支持两种分支结构(选择结构),分别是 if else 语句和 case in 语句。在《Shell if else》一节中我们讲解了 if else 语句的用法,这节我们就来讲解 case in 语句。
当分支较多,并且判断条件比较简单时,使用 case in 语句就比较方便了。
《Shell if else》一节的最后给出了一个例子,就是输入一个整数,输出该整数对应的星期几的英文表示,这节我们就用 case in 语句来重写代码,如下所示。
#!/bin/bash
printf "Input integer number: "
read num
case $num in
1)
echo "Monday"
;;
2)
echo "Tuesday"
;;
3)
echo "Wednesday"
;;
4)
echo "Thursday"
;;
5)
echo "Friday"
;;
6)
echo "Saturday"
;;
7)
echo "Sunday"
;;
*)
echo "error"
esac
运行结果: Input integer number:3↙ Wednesday
看了这个例子,相信大家对 case in 语句有了一个大体上的认识,那么,接下来我们就正式开始讲解 case in 的用法,它的基本格式如下:
case expression in pattern1) statement1 ;; pattern2) statement2 ;; pattern3) statement3 ;; …… *) statementn esac
case、in 和 esac 都是 Shell 关键字,expression 表示表达式,pattern 表示匹配模式。
- expression 既可以是一个变量、一个数字、一个字符串,还可以是一个数学计算表达式,或者是命令的执行结果,只要能够得到 expression 的值就可以。
- pattern 可以是一个数字、一个字符串,甚至是一个简单的正则表达式。
case 会将 expression 的值与 pattern1、pattern2、pattern3 逐个进行匹配:
- 如果 expression 和某个模式(比如 pattern2)匹配成功,就会执行这模式(比如 pattern2)后面对应的所有语句(该语句可以有一条,也可以有多条),直到遇见双分号
;;才停止;然后整个 case 语句就执行完了,程序会跳出整个 case 语句,执行 esac 后面的其它语句。 - 如果 expression 没有匹配到任何一个模式,那么就执行
*)后面的语句(*表示其它所有值),直到遇见双分号;;或者esac才结束。*)相当于多个 if 分支语句中最后的 else 部分。
如果你有C语言、C++、Java 等编程经验,这里的
;;和*)就相当于其它编程语言中的 break 和 default。
对*)的几点说明:
- Shell case in 语句中的
*)用来“托底”,万一 expression 没有匹配到任何一个模式,*)部分可以做一些“善后”工作,或者给用户一些提示。 - 可以没有
*)部分。如果 expression 没有匹配到任何一个模式,那么就不执行任何操作。
除最后一个分支外(这个分支可以是普通分支,也可以是*)分支),其它的每个分支都必须以;;结尾,;;代表一个分支的结束,不写的话会有语法错误。最后一个分支可以写;;,也可以不写,因为无论如何,执行到 esac 都会结束整个 case in 语句。
上面的代码是 case in 最常见的用法,即 expression 部分是一个变量,pattern 部分是一个数字或者表达式。
case in 和正则表达式
case in 的 pattern 部分支持简单的正则表达式,具体来说,可以使用以下几种格式:
| 格式 | 说明 |
|---|---|
| * | 表示任意字符串。 |
| [abc] | 表示 a、b、c 三个字符中的任意一个。比如,[15ZH] 表示 1、5、Z、H 四个字符中的任意一个。 |
| [m-n] | 表示从 m 到 n 的任意一个字符。比如,[0-9] 表示任意一个数字,[0-9a-zA-Z] 表示字母或数字。 |
| | | 表示多重选择,类似逻辑运算中的或运算。比如,abc | xyz 表示匹配字符串 "abc" 或者 "xyz"。 |
如果不加以说明,Shell 的值都是字符串,expression 和 pattern 也是按照字符串的方式来匹配的;本节第一段代码看起来是判断数字是否相等,其实是判断字符串是否相等。
最后一个分支*)并不是什么语法规定,它只是一个正则表达式,*表示任意字符串,所以不管 expression 的值是什么,*)总能匹配成功。
下面的例子演示了如何在 case in 中使用正则表达式:
#!/bin/bash
printf "Input a character: "
read -n 1 char
case $char in
[a-zA-Z])
printf "\nletter\n"
;;
[0-9])
printf "\nDigit\n"
;;
[0-9])
printf "\nDigit\n"
;;
[,.?!])
printf "\nPunctuation\n"
;;
*)
printf "\nerror\n"
esac
运行结果1: Input integer number: S letter
运行结果2: Input integer number: , Punctuation
Shell while循环语句¶
while 循环是 Shell 脚本中最简单的一种循环,当条件满足时,while 重复地执行一组语句,当条件不满足时,就退出 while 循环。
Shell while 循环的用法如下:
while condition do statements done
condition表示判断条件,statements表示要执行的语句(可以只有一条,也可以有多条),do和done都是 Shell 中的关键字。
while 循环的执行流程为:
- 先对 condition 进行判断,如果该条件成立,就进入循环,执行 while 循环体中的语句,也就是 do 和 done 之间的语句。这样就完成了一次循环。
- 每一次执行到 done 的时候都会重新判断 condition 是否成立,如果成立,就进入下一次循环,继续执行 do 和 done 之间的语句,如果不成立,就结束整个 while 循环,执行 done 后面的其它 Shell 代码。
- 如果一开始 condition 就不成立,那么程序就不会进入循环体,do 和 done 之间的语句就没有执行的机会。
注意,在 while 循环体中必须有相应的语句使得 condition 越来越趋近于“不成立”,只有这样才能最终退出循环,否则 while 就成了死循环,会一直执行下去,永无休止。
while 语句和 if else 语句中的 condition 用法都是一样的,你可以使用 test 或 [] 命令,也可以使用 (()) 或 [[]],遗忘的读者请猛击下面的链接回顾:
- Shell if else
- Shell退出状态
- Shell test命令
- [Shell []]
while 循环举例
【实例1】计算从 1 加到 100 的和。
#!/bin/bash
i=1
sum=0
while ((i <= 100))
do
((sum += i))
((i++))
done
echo "The sum is: $sum"
运行结果: The sum is: 5050
在 while 循环中,只要判断条件成立,循环就会执行。对于这段代码,只要变量 i 的值小于等于 100,循环就会继续。每次循环给变量 sum 加上变量 i 的值,然后再给变量 i 加 1,直到变量 i 的值大于 100,循环才会停止。
i++语句使得 i 的值逐步增大,让判断条件越来越趋近于“不成立”,最终退出循环。
对上面的例子进行改进,计算从 m 加到 n 的值。
#!/bin/bash
read m
read n
sum=0
while ((m <= n))
do
((sum += m))
((m++))
done
echo "The sum is: $sum"
运行结果: 1↙ 100↙ The sum is: 5050
【实例2】实现一个简单的加法计算器,用户每行输入一个数字,计算所有数字的和。
#!/bin/bash
sum=0
echo "请输入您要计算的数字,按 Ctrl+D 组合键结束读取"
while read n
do
((sum += n))
done
echo "The sum is: $sum"
运行结果: 12↙ 33↙ 454↙ 6767↙ 1↙ 2↙ The sum is: 7269
在终端中读取数据,可以等价为在文件中读取数据,按下 Ctrl+D 组合键表示读取到文件流的末尾,此时 read 就会读取失败,得到一个非 0 值的退出状态,从而导致判断条件不成立,结束循环。
Shell until循环语句¶
unti 循环和 while 循环恰好相反,当判断条件不成立时才进行循环,一旦判断条件成立,就终止循环。
until 的使用场景很少,一般使用 while 即可。
Shell until 循环的用法如下:
until condition do statements done
condition表示判断条件,statements表示要执行的语句(可以只有一条,也可以有多条),do和done都是 Shell 中的关键字。
until 循环的执行流程为:
- 先对 condition 进行判断,如果该条件不成立,就进入循环,执行 until 循环体中的语句(do 和 done 之间的语句),这样就完成了一次循环。
- 每一次执行到 done 的时候都会重新判断 condition 是否成立,如果不成立,就进入下一次循环,继续执行循环体中的语句,如果成立,就结束整个 until 循环,执行 done 后面的其它 Shell 代码。
- 如果一开始 condition 就成立,那么程序就不会进入循环体,do 和 done 之间的语句就没有执行的机会。
注意,在 until 循环体中必须有相应的语句使得 condition 越来越趋近于“成立”,只有这样才能最终退出循环,否则 until 就成了死循环,会一直执行下去,永无休止。
上节《Shell while循环》演示了如何求从 1 加到 100 的值,这节我们改用 until 循环,请看下面的代码:
#!/bin/bash
i=1
sum=0
until ((i > 100))
do
((sum += i))
((i++))
done
echo "The sum is: $sum"
运行结果: The sum is: 5050
在 while 循环中,判断条件为((i<=100)),这里将判断条件改为((i>100)),两者恰好相反,请读者注意区分。
Shell for循环语句¶
下面我们给出一个实际的例子,计算从 1 加到 100 的和。
#!/bin/bashsum=0for ((i=1; i<=100; i++))do ((sum += i))doneecho "The sum is: $sum"
运行结果: The sum is: 5050
代码分析: \1) 执行到 for 语句时,先给变量 i 赋值为 1,然后判断 i<=100 是否成立;因为此时 i=1,所以 i<=100 成立。接下来会执行循环体中的语句,等循环体执行结束后(sum 的值为1),再计算 i++。
\2) 第二次循环时,i 的值为2,i<=100 成立,继续执行循环体。循环体执行结束后(sum的值为3),再计算 i++。
\3) 重复执行步骤 2),直到第 101 次循环,此时 i 的值为 101,i<=100 不再成立,所以结束循环。
由此我们可以总结出 for 循环的一般形式为:
for(( 初始化语句; 判断条件; 自增或自减 )) do statements done
for 循环中的三个表达式
for 循环中的 exp1(初始化语句)、exp2(判断条件)和 exp3(自增或自减)都是可选项,都可以省略(但分号;必须保留)。
\1) 修改“从 1 加到 100 的和”的代码,省略 exp1:
#!/bin/bash
sum=0
i=1
for ((; i<=100; i++))
do
((sum += i))
done
echo "The sum is: $sum"
可以看到,将i=1移到了 for 循环的外面。
\2) 省略 exp2,就没有了判断条件,如果不作其他处理就会成为死循环,我们可以在循环体内部使用 break 关键字强制结束循环:
#!/bin/bash
sum=0
for ((i=1; ; i++))
do
if(( i>100 )); then
break
fi
((sum += i))
done
echo "The sum is: $sum"
break 是 Shell 中的关键字,专门用来结束循环,后续章节还会深入讲解。
\3) 省略了 exp3,就不会修改 exp2 中的变量,这时可在循环体中加入修改变量的语句。例如:
#!/bin/bash
sum=0
for ((i=1; i<=100; ))
do
((sum += i))
((i++))
done
echo "The sum is: $sum"
\4) 最后给大家看一个更加极端的例子,同时省略三个表达式:
#!/bin/bash
sum=0
i=0
for (( ; ; ))
do
if(( i>100 )); then
break
fi
((sum += i))
((i++))
done
echo "The sum is: $sum"
这种写法并没有什么实际意义,仅仅是为了给大家做演示。
Shell select循环语句¶
select in 循环用来增强交互性,它可以显示出带编号的菜单,用户输入不同的编号就可以选择不同的菜单,并执行不同的功能。
select in 是 Shell 独有的一种循环,非常适合终端(Terminal)这样的交互场景,C语言、C++、Java、Python、C# 等其它编程语言中是没有的。
Shell select in 循环的用法如下:
select variable in value_list do statements done
variable 表示变量,value_list 表示取值列表,in 是 Shell 中的关键字。你看,select in 和 for in 的语法是多么地相似。
我们先来看一个 select in 循环的例子:
#!/bin/bash
echo "What is your favourite OS?"
select name in "Linux" "Windows" "Mac OS" "UNIX" "Android"
do
echo $name
done
echo "You have selected $name"
运行结果:
What is your favourite OS? \1) Linux \2) Windows \3) Mac OS \4) UNIX \5) Android #? 4↙ You have selected UNIX #? 1↙ You have selected Linux #? 9↙ You have selected #? 2↙ You have selected Windows #?^D
#?用来提示用户输入菜单编号;^D表示按下 Ctrl+D 组合键,它的作用是结束 select in 循环。
运行到 select 语句后,取值列表 value_list 中的内容会以菜单的形式显示出来,用户输入菜单编号,就表示选中了某个值,这个值就会赋给变量 variable,然后再执行循环体中的 statements(do 和 done 之间的部分)。
每次循环时 select 都会要求用户输入菜单编号,并使用环境变量 PS3 的值作为提示符,PS3 的默认值为#?,修改 PS3 的值就可以修改提示符。
如果用户输入的菜单编号不在范围之内,例如上面我们输入的 9,那么就会给 variable 赋一个空值;如果用户输入一个空值(什么也不输入,直接回车),会重新显示一遍菜单。
注意,select 是无限循环(死循环),输入空值,或者输入的值无效,都不会结束循环,只有遇到 break 语句,或者按下 Ctrl+D 组合键才能结束循环。
完整实例
select in 通常和 case in 一起使用,在用户输入不同的编号时可以做出不同的反应。
修改上面的代码,加入 case in 语句:
#!/bin/bash
echo "What is your favourite OS?"
select name in "Linux" "Windows" "Mac OS" "UNIX" "Android"
do
case $name in
"Linux")
echo "Linux是一个类UNIX操作系统,它开源免费,运行在各种服务器设备和嵌入式设备。"
break
;;
"Windows")
echo "Windows是微软开发的个人电脑操作系统,它是闭源收费的。"
break
;;
"Mac OS")
echo "Mac OS是苹果公司基于UNIX开发的一款图形界面操作系统,只能运行与苹果提供的硬件之上。"
break
;;
"UNIX")
echo "UNIX是操作系统的开山鼻祖,现在已经逐渐退出历史舞台,只应用在特殊场合。"
break
;;
"Android")
echo "Android是由Google开发的手机操作系统,目前已经占据了70%的市场份额。"
break
;;
*)
echo "输入错误,请重新输入"
esac
done
用户只有输入正确的编号才会结束循环,如果输入错误,会要求重新输入。
运行结果1,输入正确选项:
What is your favourite OS? \1) Linux \2) Windows \3) Mac OS \4) UNIX \5) Android #? 2 Windows是微软开发的个人电脑操作系统,它是闭源收费的。
运行结果2,输入错误选项:
What is your favourite OS? \1) Linux \2) Windows \3) Mac OS \4) UNIX \5) Android #? 7 输入错误,请重新输入 #? 4 UNIX是操作系统的开山鼻祖,现在已经逐渐退出历史舞台,只应用在特殊场合。
运行结果3,输入空值:
What is your favourite OS? \1) Linux \2) Windows \3) Mac OS \4) UNIX \5) Android #? \1) Linux \2) Windows \3) Mac OS \4) UNIX \5) Android #? 3 Mac OS是苹果公司基于UNIX开发的一款图形界面操作系统,只能运行与苹果提供的硬件之上。
Shell break关键字¶
Shell break 关键字的用法为:
break n
n 表示跳出循环的层数,如果省略 n,则表示跳出当前的整个循环。break 关键字通常和 if 语句一起使用,即满足条件时便跳出循环。
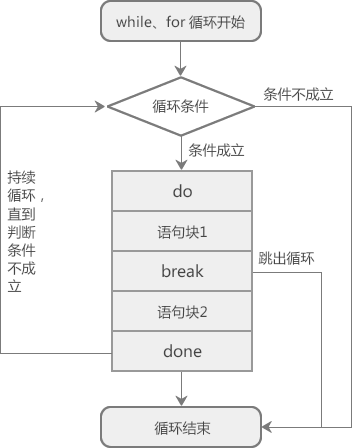 图1:Shell break关键字原理示意图
图1:Shell break关键字原理示意图
【实例1】不断从终端读取用户输入的正数,求它们相加的和:
#!/bin/bashsum=0while read n; do if((n>0)); then ((sum+=n)) else break fidoneecho "sum=$sum"
运行结果: 10↙ 20↙ 30↙ 0↙ sum=60
while 循环通过 read 命令的退出状态来判断循环条件是否成立,只有当按下 Ctrl+D 组合键(表示输入结束)时,read n才会判断失败,此时 while 循环终止。
除了按下 Ctrl+D 组合键,你还可以输入一个小于等于零的整数,这样会执行 break 语句来终止循环(跳出循环)。
【实例2】使用 break 跳出双层循环。
如果 break 后面不跟数字的话,表示跳出当前循环,对于有两层嵌套的循环,就得使用两个 break 关键字。例如,输出一个 4*4 的矩阵:
#!/bin/bashi=0while ((++i)); do #外层循环 if((i>4)); then break #跳出外层循环 fi j=0; while ((++j)); do #内层循环 if((j>4)); then break #跳出内层循环 fi printf "%-4d" $((i*j)) done printf "\n"done
运行结果:
1 2 3 4
2 4 6 8
3 6 9 12
4 8 12 16
当 j>4 成立时,执行第二个 break,跳出内层循环;外层循环依然执行,直到 i>4 成立,跳出外层循环。内层循环共执行了 4 次,外层循环共执行了 1 次。
我们也可以在 break 后面跟一个数字,让它一次性地跳出两层循环,请看下面的代码:
#!/bin/bashi=0while ((++i)); do #外层循环 j=0; while ((++j)); do #内层循环 if((i>4)); then break 2 #跳出内外两层循环 fi if((j>4)); then break #跳出内层循环 fi printf "%-4d" $((i*j)) done printf "\n"done
修改后的代码将所有 break 都移到了内层循环里面。读者需要重点关注break 2这条语句,它使得程序可以一次性跳出两层循环,也就是先跳出内层循环,再跳出外层循环。
shell continue关键字¶
Shell continue 关键字的用法为:
continue n
n 表示循环的层数:
- 如果省略 n,则表示 continue 只对当前层次的循环语句有效,遇到 continue 会跳过本次循环,忽略本次循环的剩余代码,直接进入下一次循环。
- 如果带上 n,比如 n 的值为 2,那么 continue 对内层和外层循环语句都有效,不但内层会跳过本次循环,外层也会跳过本次循环,其效果相当于内层循环和外层循环**同时**执行了不带 n 的 continue。这么说可能有点难以理解,稍后我们通过代码来演示。
continue 关键字也通常和 if 语句一起使用,即满足条件时便跳出循环。
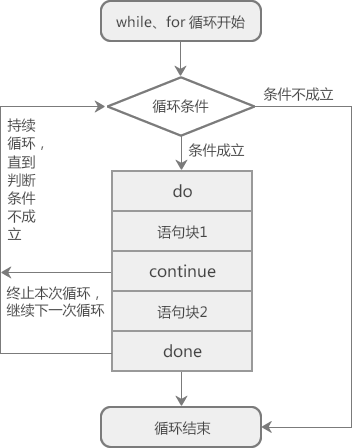 图2:Shell continue关键字原理示意图
图2:Shell continue关键字原理示意图
【实例1】不断从终端读取用户输入的 100 以内的正数,求它们的和:
#!/bin/bashsum=0while read n; do if((n<1 || n>100)); then continue fi ((sum+=n))doneecho "sum=$sum"
运行结果: 10↙ 20↙ -1000↙ 5↙ 9999↙ 25↙ sum=60
变量 sum 最终的值为 60,-1000 和 9999 并没有计算在内,这是因为 -1000 和 9999 不在 1~100 的范围内,if 判断条件成立,所以执行了 continue 语句,跳过了当次循环,也就是跳过了((sum+=n))这条语句。
注意,只有按下 Ctrl+D 组合键输入才会结束,read n才会判断失败,while 循环才会终止。
【实例2】使用 continue 跳出多层循环,请看下面的代码:
#!/bin/bashfor((i=1; i<=5; i++)); do for((j=1; j<=5; j++)); do if((i*j==12)); then continue 2 fi printf "%d*%d=%-4d" $i $j $((i*j)) done printf "\n"done
运行结果:
1*1=1 1*2=2 1*3=3 1*4=4 1*5=5
2*1=2 2*2=4 2*3=6 2*4=8 2*5=10
3*1=3 3*2=6 3*3=9 4*1=4 4*2=8 5*1=5 5*2=10 5*3=15 5*4=20 5*5=25
从运行结果可以看出,遇到continue 2时,不但跳过了内层 for 循环,也跳过了外层 for 循环。
break 和 continue 的区别¶
break 用来结束所有循环,循环语句不再有执行的机会;continue 用来结束本次循环,直接跳到下一次循环,如果循环条件成立,还会继续循环。
Shell函数详解¶
Shell 函数的本质是一段可以重复使用的脚本代码,这段代码被提前编写好了,放在了指定的位置,使用时直接调取即可。
Shell 中的函数和C++、Java、Python、C# 等其它编程语言中的函数类似,只是在语法细节有所差别。
Shell 函数定义的语法格式如下:
function name() { statements [return value] }
对各个部分的说明:
function是 Shell 中的关键字,专门用来定义函数;name是函数名;statements是函数要执行的代码,也就是一组语句;return value表示函数的返回值,其中 return 是 Shell 关键字,专门用在函数中返回一个值;这一部分可以写也可以不写。
由{ }包围的部分称为函数体,调用一个函数,实际上就是执行函数体中的代码。
函数定义的简化写法
如果你嫌麻烦,函数定义时也可以不写 function 关键字:
name() { statements [return value] }
如果写了 function 关键字,也可以省略函数名后面的小括号:
function name { statements [return value] }
我建议使用标准的写法,这样能够做到“见名知意”,一看就懂。
函数调用
调用 Shell 函数时可以给它传递参数,也可以不传递。如果不传递参数,直接给出函数名字即可:
name
如果传递参数,那么多个参数之间以空格分隔:
name param1 param2 param3
不管是哪种形式,函数名字后面都不需要带括号。
和其它编程语言不同的是,Shell 函数在定义时不能指明参数,但是在调用时却可以传递参数,并且给它传递什么参数它就接收什么参数。
Shell 也不限制定义和调用的顺序,你可以将定义放在调用的前面,也可以反过来,将定义放在调用的后面。
实例演示
\1) 定义一个函数,输出 Shell 教程的地址:
#!/bin/bash#函数定义function url(){ echo "http://c.biancheng.net/shell/"}#函数调用url
运行结果: http://c.biancheng.net/shell/
你可以将调用放在定义的前面,也就是写成下面的形式:
#!/bin/bash#函数调用url#函数定义function url(){ echo "http://c.biancheng.net/shell/"}
\2) 定义一个函数,计算所有参数的和:
#!/bin/bashfunction getsum(){ local sum=0 for n in $@ do ((sum+=n)) done return $sum}getsum 10 20 55 15 #调用函数并传递参数echo $?
运行结果: 100
$@表示函数的所有参数,$?表示函数的退出状态(返回值)。关于如何获取函数的参数,我们将在《Shell函数参数》一节中详细讲解。
此处我们借助 return 关键字将所有数字的和返回,并使用$?得到这个值,这种处理方案在其它编程语言中没有任何问题,但是在 Shell 中是非常错误的,Shell 函数的返回值和其它编程语言大有不同,我们将在《Shell函数返回值》中展开讨论。